11
Apr
2022
pgModeler 1.0.0-alpha is finally here!
The beginning of a new phase in the project's development
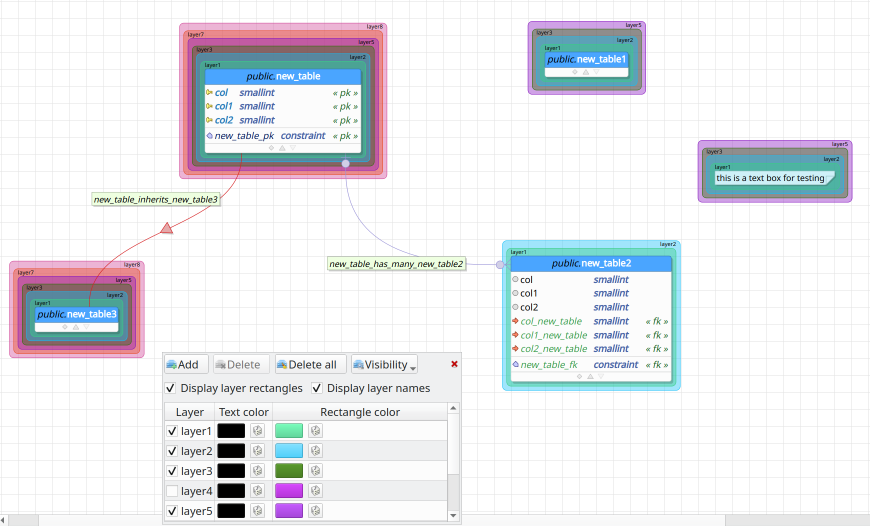
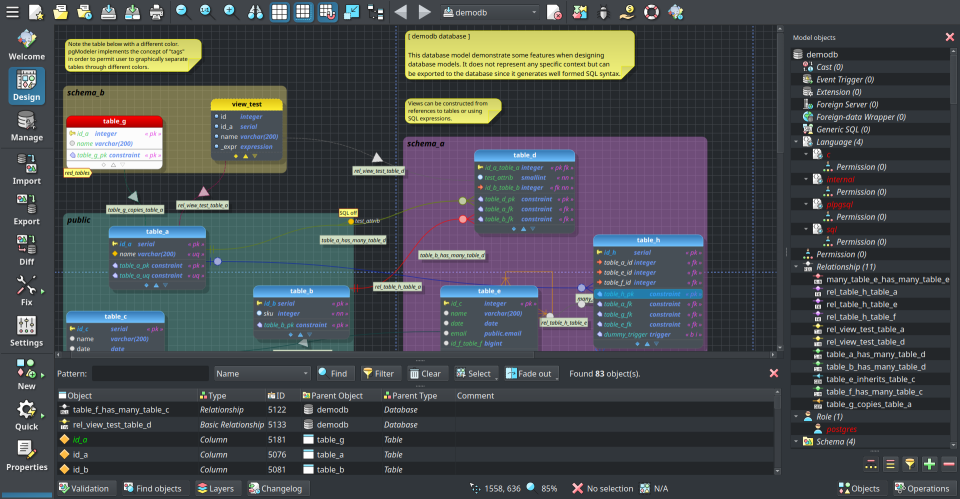
After four long months of working, we finally have the first alpha release of pgModeler 1.0! The main goal of this version was to boot up a series of deep improvements in the UI adding visual comfort while using the software. So that was done, this one brings redesigned UI elements and colors, a completely new icon set, and officially introduces the new project logo. As promised, pgModeler 1.0.0-alpha brings a responsive UI adapting the widget sizes and icons according to the screen's resolution. Also, we now have the support for color themes which can be toggled on-the-fly in the appearance settings. I'll explain more about what's new in the full post, don't miss it!