The DTD (document type definition) structure of the database model file has changed since 0.9.3-beta. Models created in previous releases will certainly fail to load due to incompatibilities because some attributes in the XML code does not exist anymore or have changed on 0.9.3-beta1. Before loading your database models in this new release, please, make sure to have a backup of all of them and follow the steps presented by the tool to fix the documents' contents. Not paying attention to this situation may cause irreversible data loss! If the fix procedures aren't enough to make your database model loadable again, please, ask for help at the official support channels!
I'm glad to announce that we are almost closing another development cycle. Unfortunately, this one took more time than I expected because I had some problems with my old development machine, which forced me to buy a new one. The entire process took more than one month, which significantly impacted the release scheduling of pgModeler 0.9.3-beta1. The feature set of this release was practically ready (pending only a few tests) when my computer had broke. But the fact of being idle for a certain amount of time made me thought about some other improvements I was planning to add only in future versions that could be implemented still in 0.9.3-beta1. So, I decided to delay a little bit the launching of this version to work on those features. Let's see below some of them!
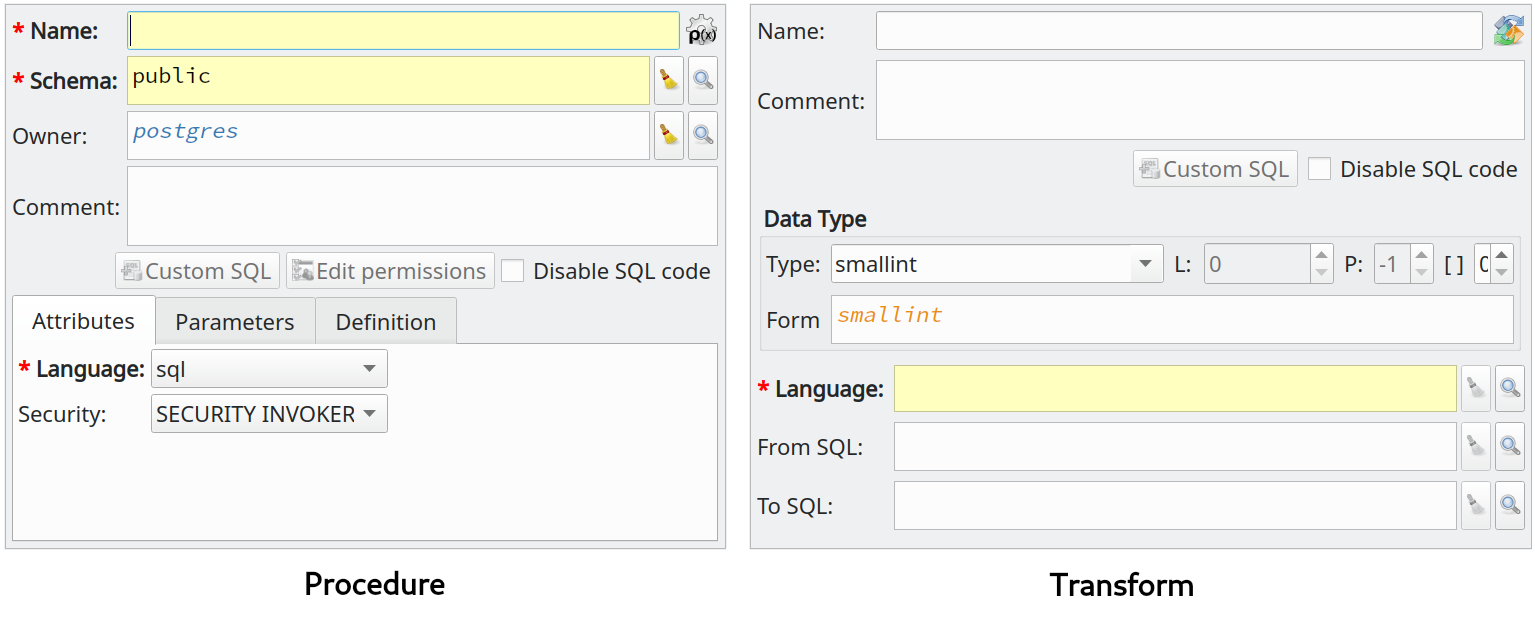
Procedures and transforms support
One of the main goals of this project is to support as many as possible objects backed by PostgreSQL. So, I decided to include procedures and transforms, totalizing 33 known object kinds.
Procedures are "almost" like the ordinary functions except for the fact that they can run in a transaction block and can't return values as functions do. There are other essential differences, but I recommend you to go deeper into the official docs for more information. The implementation of procedures in pgModeler's core was quick since both objects are very similar.
A transform, as stated by the PostgreSQL docs, specifies how to adapt a data type to a procedural language. For example, when writing a function in PL/Python using the hstore type, PL/Python has no prior knowledge on how to present hstore values in the Python environment. Language implementations usually default to using the text representation. If you need any special treatment of a data type in a procedural language environment, a transform object is ideal for this task.
It's not much to remind that specific versions of PostgreSQL support procedures and transforms, in this case, 11+ for the former and 9.5+ for the latter. So, if you intend to use these objects in your database models, make sure to export the code to a compatible DBMS version to avoid problems.
Code generation changes
The SQL code generation for the database object changed in this version. Before 0.9.3-beta1, the code was always disabled either in SQL preview or when exporting to a script file ignoring completely the disabled status defined by the user. Now, to respect that condition, the CREATE DATABASE statement and any appended or prepended code will follow the disabled status defined by the user. This is not valid for the validation process, which needs to always activate the mentioned command to validate the model's structure correctly.
Due to this change, the model export dialog will fail every time the user tries to export a model in which the database object is disabled. So pay attention to this fact to avoid surprises when using the tools that pgModeler provides to export your database model quickly either in graphical interface or command-line interface.
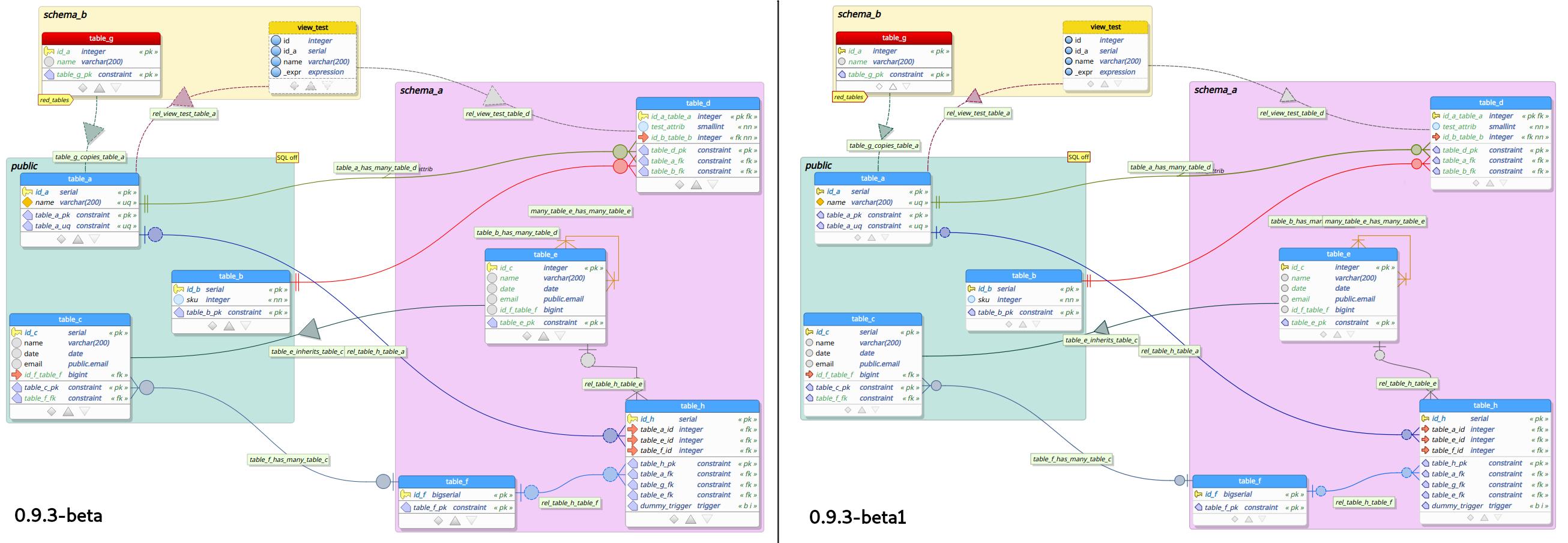
Improved rendering in high DPI screens
Switching to a new PC (specifically to a wider monitor) led me to see some problems that I wasn't aware of when working on a full HD or 2K display. One of those problems was the improper resizing of objects in the design view when an increased font DPI was in use, or even the special environment variable QT_AUTO_SCREEN_SCALE_FACTOR was set. As the image below shows us in the left portion, pgModeler was rendering column descriptors, relationship indicators, and many other objects in the wrong proportions affecting the viewing of the database models. So, after applying a fix, pgModeler now renders everything as we expect, as demonstrated in the right portion of the image.
Miscellaneous.
Other fixes and changes that worth mentioning is that pgModeler now will not generate ADD CONSTRAINT instructions related to constraints (check and unique ones) during the diff process when the parent table is also being created in the process. This will avoid trying to create twice the same objects, which may break the entire diff applying.
Another improvement brought by this new version is that default values and functions arguments containing JSON values are now correctly formatted and saved to the XML code avoiding corruption of the database model in very specific cases.
The appearance of the objects in the design view is now more flexible, and the user can specify custom colors for pagination toggler at the bottom of the tables. This increment is also applied to tag objects, which now can carry custom colors for the mentioned elements that will be applied to tables associated with those tags.
To avoid losses, pgModeler now checks if the same database model is open in different tabs in the design view and will alert the user about the risk of losing the work when saving an older version of the model over a recent one.
Finally, there were several fixes in the reverse engineering feature minimizing the failures when importing different arrangements of databases.
In celebration of this new release, you can get the precompiled installers with a super discount by using the promo code ENJOY12OFF (valid until November, 5) and help to keep the gears of this project turning around. Don't waste time, grab a ready-to-use copy of pgModeler here, or, if you prefer, you can get the source code here and use the installation instructions to build it on your computer.
Well, that's it! I'm glad to see how mature pgModeler is now and how fantastic are the feedback that I'm receiving either in email, GitHub, or Twitter. I'm even starting to plan some improvements for version 1.0, but this is the subject of another post. From now on, since the feature set is good enough for this series, I'll be working only on bug fixes in preparation for the stable release of 0.9.3. I hope you enjoy pgModeler 0.9.3-beta1 and, of course, leave your comments so we can improve this project together!
Until next time!
Martin
October 16, 2020 at 15:50:08
Cara, sem comentários. Pgmodeler é de longe a melhor ferramenta para construção e manutenção de banco de dados pgsql.. já testei uma cacetada e sério, sem comparação. Parabéns, assim que meu projeto decolar vou comprar p/ ajudar!
Raphael Araújo e Silva
October 22, 2020 at 22:10:47
Muito obrigado, Martin. Fico extremamente feliz quando recebo esse tipo de feedback. É bom saber que o fruto do meu trabalho tem ajudado outros desenvolvedores pelo mundo! :)
Jim
December 12, 2020 at 15:47:15
How would you like to receive suggested changes, not to pgModeler itself, but to the accompanying help and tutorial documentation?
Raphael Araújo e Silva
December 15, 2020 at 11:39:15
Hi Jim!
You can suggest changes on the docs at GitHub too: https://github.com/pgmodeler/pgmodeler/issues
Thanks!
Add new comment