Hey there! Here we are, gladly announcing a new stable release of pgModeler after one year and three months of hard work to deliver a rock-solid product, marking the end of the development cycle of the series 1.2.x, and in a few weeks, I'll boot up the initial work on pgModeler 2.0! This release brings an even more optimized tool, with features that will make a difference in any aspect of database modeling and administration! Below, we have a compilation of key new features, changes, and fixes implemented since pgModeler 1.1.0. Of course, some more technical details were omitted, but you can see everything in the file CHANGELOG.md.
Improved source code editor
The source code editor field received two new features. First, there is an embedded search/replace widget - its functionality is self-explanatory. The second addition is a line wrap feature that automatically breaks lines to fit the widget's width. This functionality makes editing code with long lines more convenient by eliminating the need for horizontal scrolling. Both features can be activated from the actions bar available in every source code editor widget.
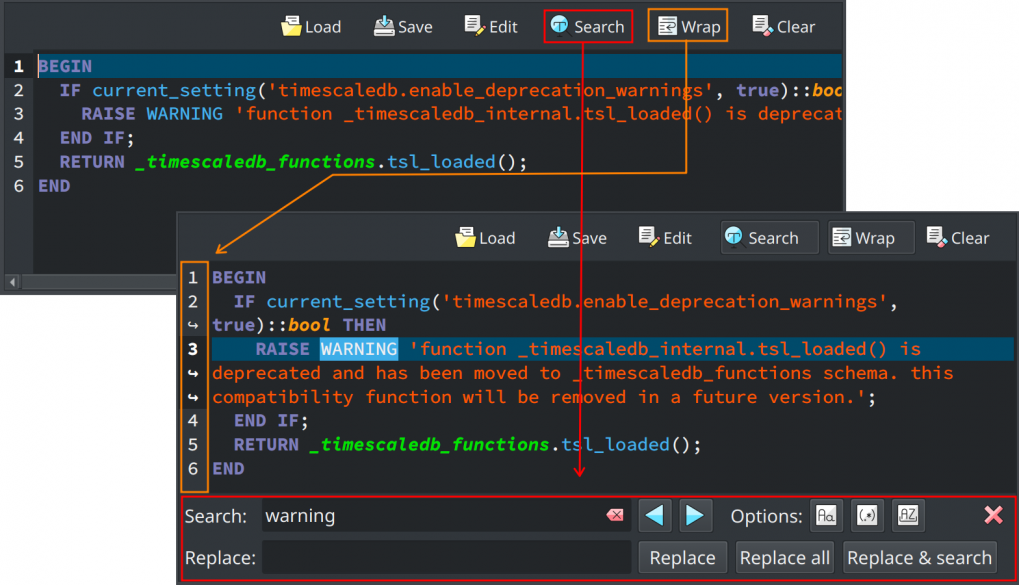
Improved debug mode
The reverse engineering and database diff forms now show a debug tab during debug mode operations. This helps users troubleshoot problems by providing detailed information about the processes' execution when things don't work as expected.
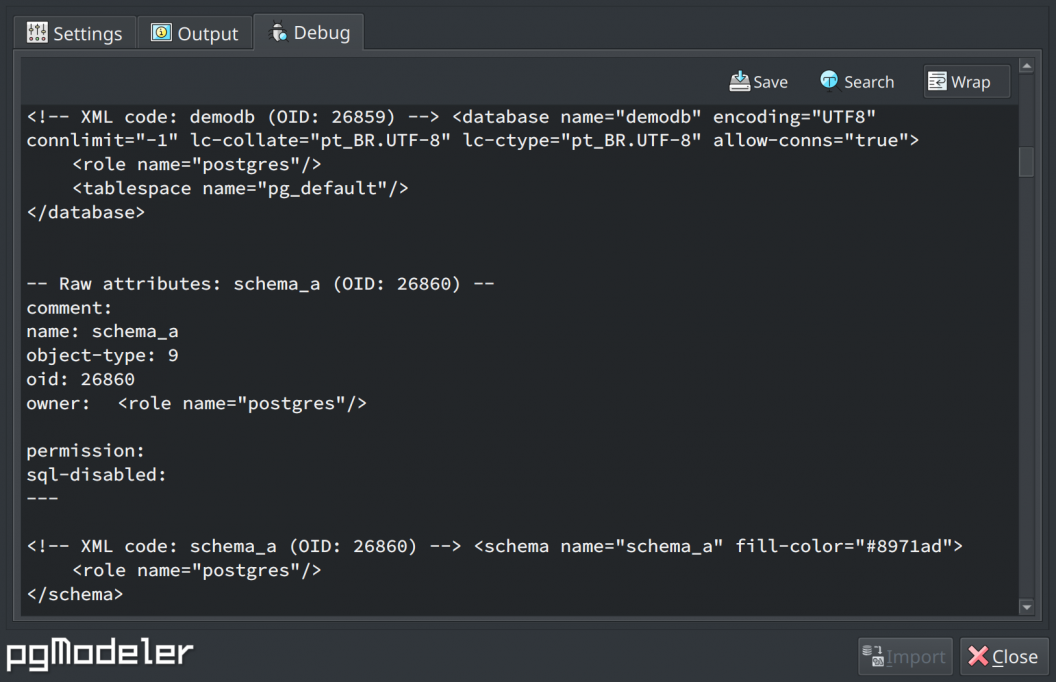
Enhanced extension child object handling
This release brings significant improvements to how pgModeler handles PostgreSQL extensions, addressing a crucial need for users who regularly work with extension ecosystems. Extensions in PostgreSQL can manage several database objects in multiple schemas, but until now, pgModeler's implementation was limited primarily to data types and contained an important architectural limitation - it incorrectly bound these objects to the extension's installation schema rather than their proper locations.
The new version introduces an improved extension awareness that properly handles complex scenarios like timescaledb, where an extension installed in the public schema creates and manages objects in dedicated schemas such as _timescaledb_internal, for example. Previously, attempting to import databases using such extensions could produce incomplete models or fail completely, as the tool couldn't properly represent these schema relationships.
The below image demonstrates this improvement, clearly showing how timescaledb installed in the public schema correctly owns and manages data types residing in the separate _timescaledb_internal schema - a relationship that previous versions would have misinterpreted. This fundamental improvement in extension handling makes pgModeler far more reliable for databases leveraging PostgreSQL's powerful extension system. For future releases, there will be support for other objects like operations, operation classes, functions, procedures, and many others.
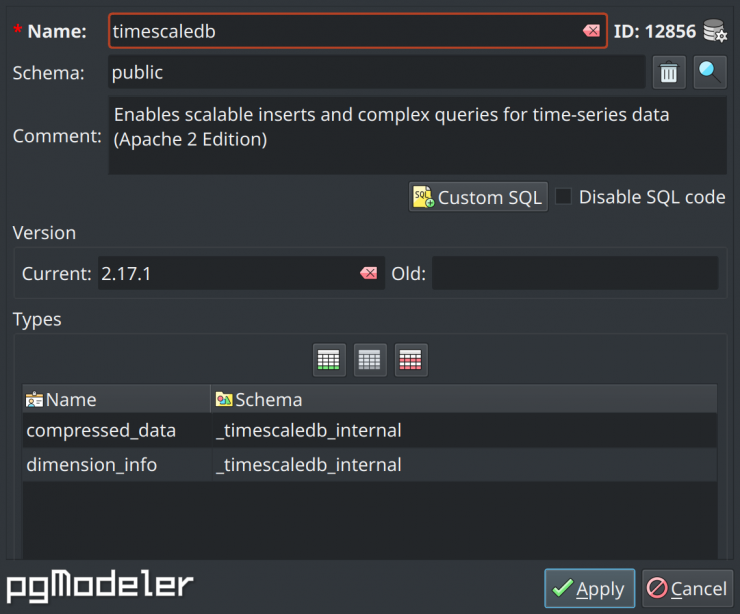
Relationships' FK columns indexes
Now, relationships that automatically create foreign key columns can also create indexes over those columns, which can speed up the modeling process a bit more. To enable an index over a foreign key column generated by a relationship, just select the indexing mode (a.k.a access method) in the tab Settings on the relationship dialog. Once the settings are applied, the index will be automatically generated (see below). Like relationships, the generated indexes are named after a specific pattern, and the user has total control over the generated names in the relationship editing form or by defining a global name pattern under relationship settings.
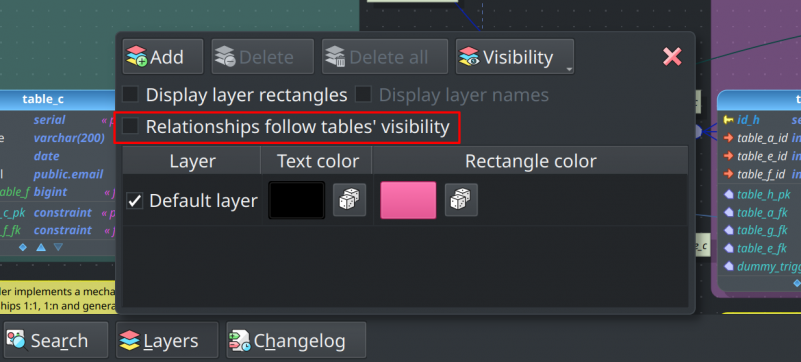
Improved layers setup
The operation to move objects to certain layers was significantly improved in this version. Now, the quick action Quick > Set layers opens a dialog where the user can move the selected objects to one or more existing layers or even create layers on the fly and assign them to the selected objects in the design view.
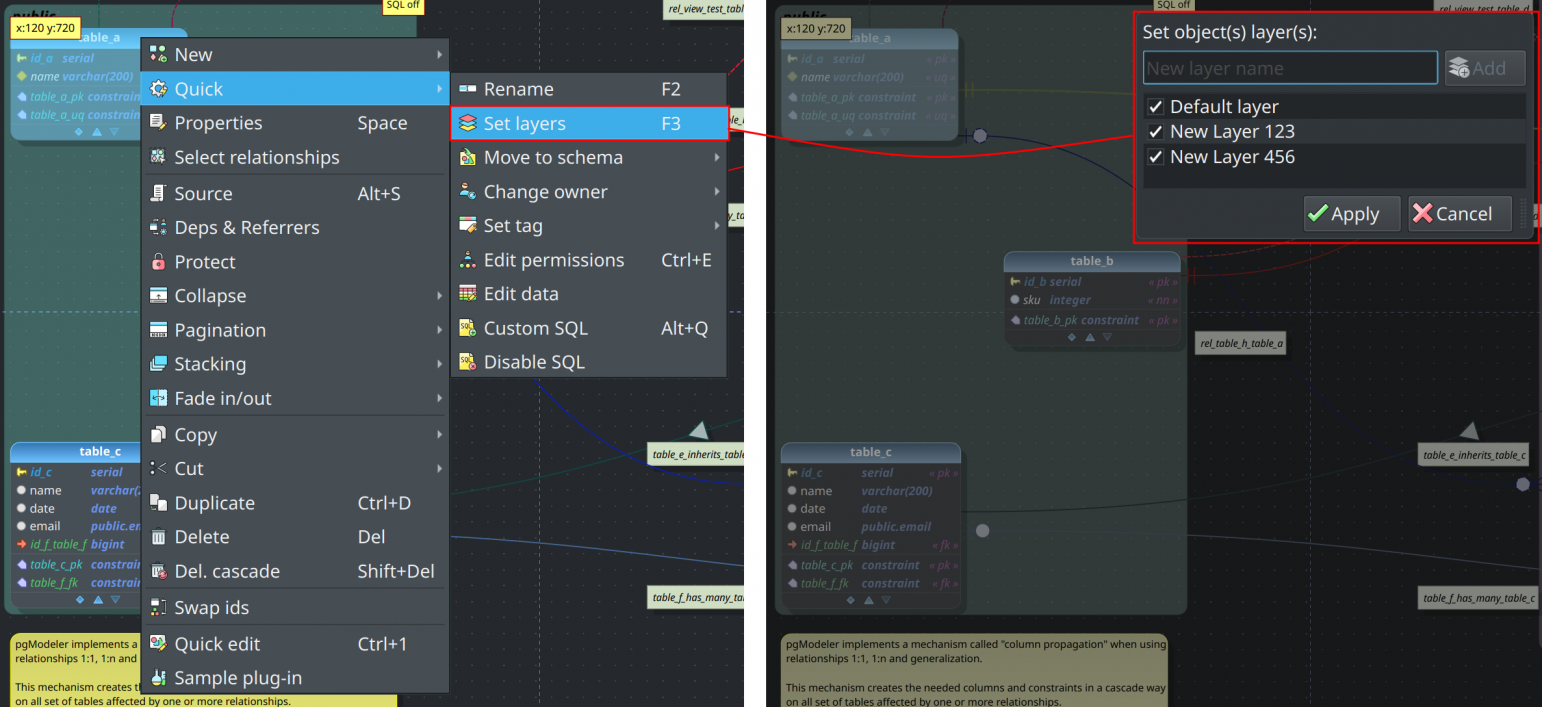
Additionally to that improvement, the layers configuration widget (the one that is toggled by the button Layers at the bottom of the design view) received an option that makes relationships follow the visibility of the linked tables. This means that if one table is moved to a layer the relationships connected to it will move to that layer too, being hidden or displayed depending on the layer's visibility state.
Transactional export process
The export process is now capable of running the commands at once inside a transaction block. This is useful if you want an atomic execution of the generated DDLs, rolling back everything if one command fails in its execution. Note that the transactional option does not affect database and tablespace creation commands, since, by design, these commands need to be executed outside a transaction. This feature is also available on the diff process in the export to DBMS step, under the options group Export options.
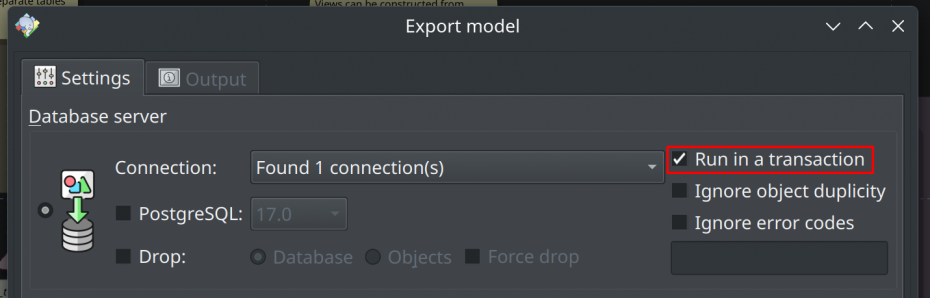
The command-line interface tool also received support for the transactional export process, and it's enabled by default, like in the GUI. To deactivate it during the execution of any export operation, use the options -nt or --non-transactional.
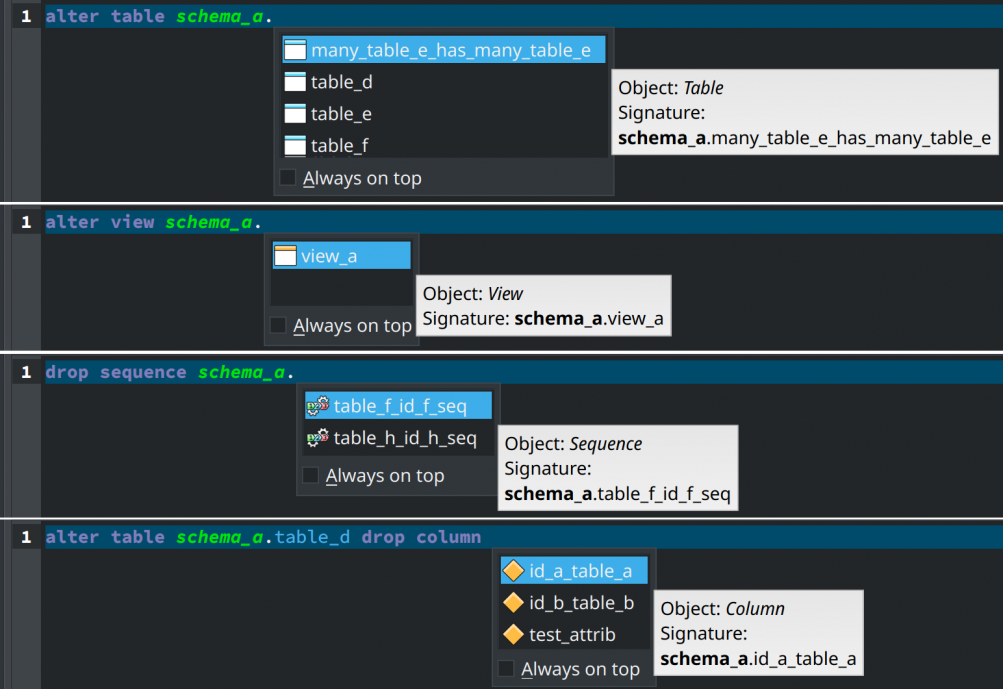
Improved code completion
The code completion widget now supports the completion of names in ALTER and DROP commands. It also detects the type of objects being modified or dropped, suggesting the names filtered by the specified types. In addition to that, the code completion is now capable of suggesting column names after the ORDER BY clause.
Tabbed data handling
Before this version, data manipulation was performed via standalone dialogs, which could make data handling more difficult due to the number of windows open. Now, all browsed tables are reunited in a single dialog but are displayed in their own tabs, facilitating data visualization. By the way, you still can use separate windows to handle tables' data by clicking the button ![]() or hitting
or hitting Ctrl+N.
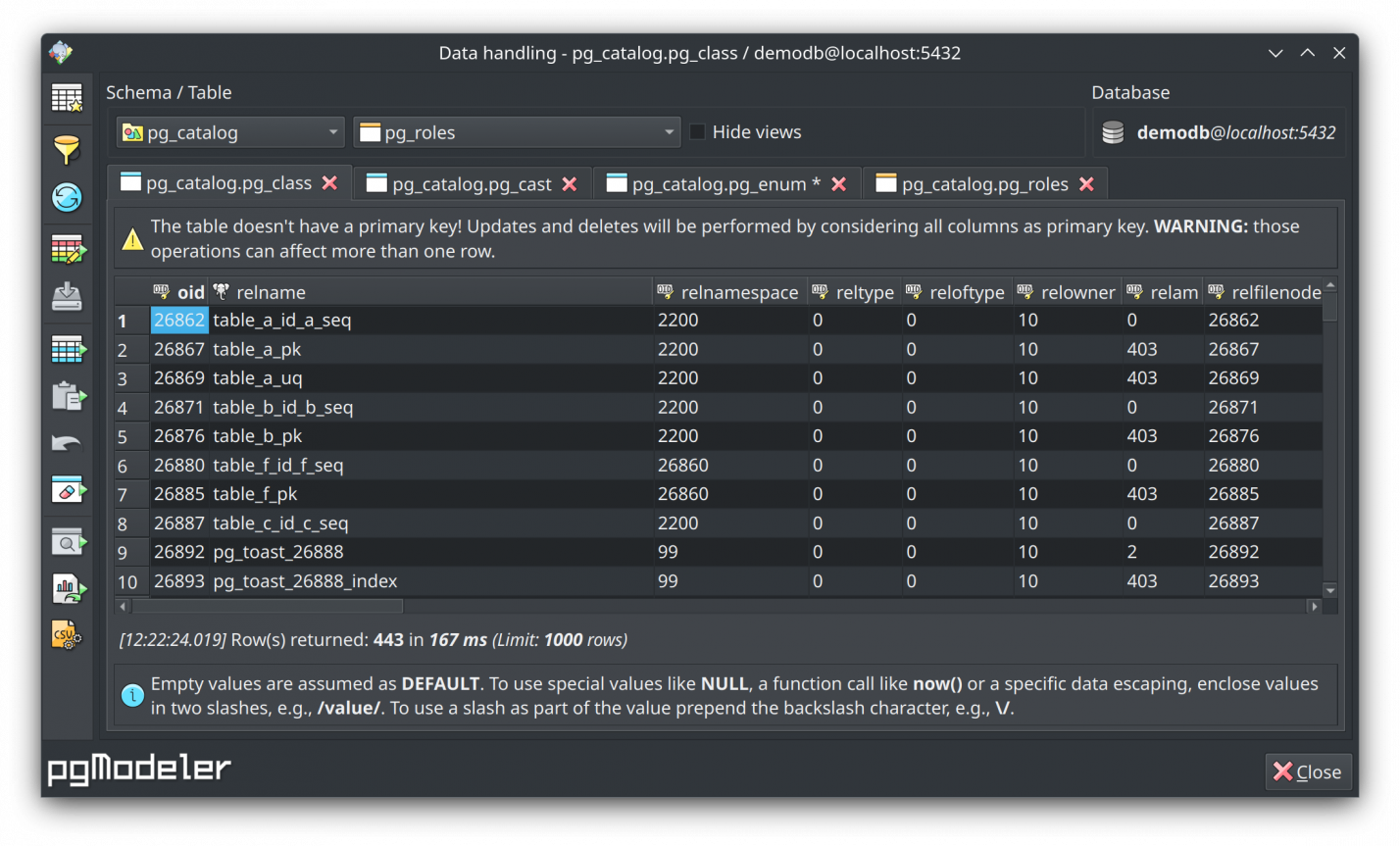
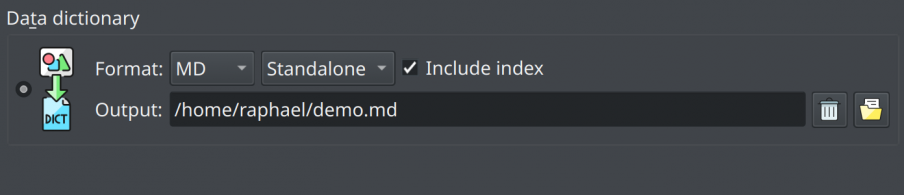
Markdown data dictionaries
pgModeler now supports the generation of data dictionaries in Markdown (.md) format in the model export form. This is useful to integrate data dictionaries generated by the tool with other documentation tools that use that file format to keep documentation pages. The pgmodeler-cli tool also received support for Markdown dictionaries through the option --markdown.
Improved code generation
The DDL generation for objects that support CREATE OR REPLACE was updated to include the OR REPLACE portion. This is the case for functions, procedures, views, and others. The diff feature received the option "Replace modified objects", which causes objects to be replaced via CREATE OR REPLACE instead of being dropped and created again.
Improved older configs copy
From now on, in the first run, pgModeler will try to copy the configuration files from a previous major version immediately before the current one. For example, running 1.2, the files to be copied will be from 1.1 and not from 0.9.x anymore. This will increase the chances of reusing settings from previous versions, diminishing the annoying situation of reconfiguring the tool every time it is updated.
Improved schema microlanguage
The pgModeler's code templating language (aka schema microlanguage) was improved in such a way as to support escaped character sequences that refer to metacharacter tokens. The supported escaped characters (and their related metacharacters) are \s ($sp), \t ($tb), \n ($br), \[ ($ob), \] ($cb), \{ ($oc), \} ($cc), \$ ($ds), \# ($hs), \% ($ps), \@ ($at), \& ($am), \\ ($bs) and \* ($ds). The schema language also supports the @include statements that inject portions of code stored in other files into the currently parsed schema file. This is pretty handy for avoiding code duplication and facilitating the maintenance of schema files.
Improved plugin development API
The pgModeler's plugin development interface was improved and now allows more portions of the tool to receive user-created features to increase its set of functionalities. Unfortunately, for now, you still need a basic knowledge of C++ and Qt. But for future releases, I plan to simplify even more the plugin interface in such a way as to allow non-C++ developers to create their custom features for pgModeler. You can get more details about plugin development in the official docs.
Query variables plugin
pgModeler Plus received a new plugin that helps the developers test their queries using variables that are replaced in the commands at the moment of their execution. Basically, a query that contains some variables prefixed by $, like in SELECT $cols FROM $schema.$table WHERE $condition has the values for each variable replaced and the parsed query executed. The variables and their values can be specified in a special widget that is toggled by the button Variables in the SQL execution widget. The main goal of this new feature is to accelerate the query testing, mainly if you write parametrized queries based on some ORMs' syntaxes. This plugin supports four variable formats: $variable, :variable, @variable, and {variable}.
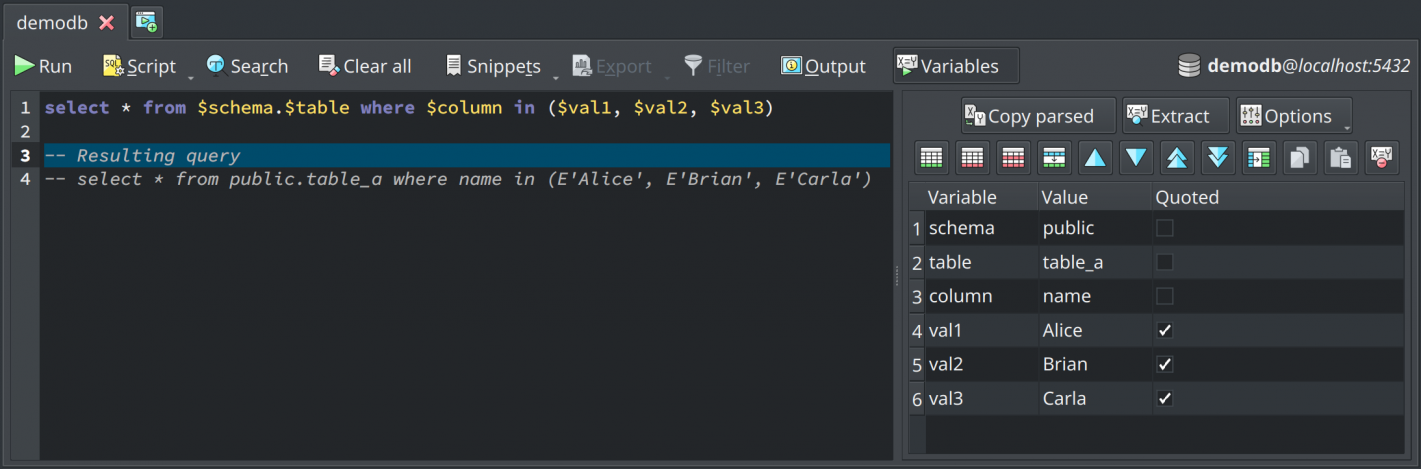
The button Copy parsed copies to the clipboard the resulting query after parsing the original one, replacing the variables with their values. Now, theExtract button performs a scan in the original query looking for variable patterns, and, once found, puts each result in the variables grid so the user can specify test values for them. The button Options holds a dropdown menu containing two options. The first one, Empty values translate to NULL, causes empty-valued variables to be replaced by the keyword NULL. The second option, Escape quoted values with E'', forces the use of the special string quoting syntax that allows the use of C-Style constants within strings.
In the variables grid, we have the column Variable, which is the variable's name. Note that despite the variables in the original query being suffixed by a special character (e.g. $, @, :), there's no need to include that suffix in the variable name. During the query parsing, pgModeler will automatically prepend the accepted suffixes in the variable names and replace them accordingly. Also, duplicated variable names in the grid are accepted, but only the first value will be considered during the parsing. The column Value holds the variable's value that will be replaced in the original query. Beware that this field is completely free of any validation. In that case, the user is responsible for any character formatting and/or escaping. Data type values or even SQL keywords are accepted in this column. Finally, the column Quoted, is a convenience feature that automatically encloses the value of the respective column in quotes (this is affected by the option Escape quoted values with E'').
Quick create constraints, indexes, and relationships
This feature, introduced through an exclusive plugin in pgModeler Plus, allows the creation of constraints, indexes, and relationships based on the objects selected in the design view without the need to open a single editing form or fill out many fields. The objects created also support name patterns, which can be configured in the plugin's settings menu in the main window.
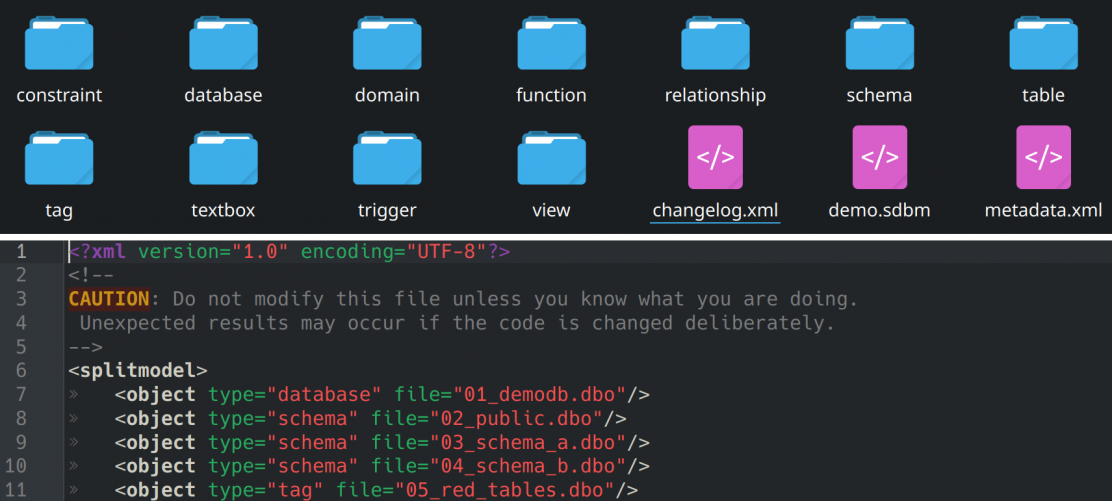
Split model file specification changes
In pgModeler Plus, the split database model format specification was changed to fix some problems when the model, when managed by a source code management system, was handled by several people. In some circumstances, the merge operations would cause the corruption of the index file (.sdbm), leading to loading failures.
The major change in the sdbm format involves separating database model metadata (author, layer settings, and other attributes) into a dedicated metadata.xml file. The .sdbm file has been simplified to contain only references to the model's component files, and the changelog file has been renamed to changelog.xml. Note that loading a split model now requires both metadata.xml and .sdbm files to be present in the same folder - the operation will fail if either is missing.
This format change introduces a backward compatibility limitation: pgModeler 1.2.0-beta1 cannot read split models created in previous versions. To migrate existing split models to the new format, follow this procedure using your current pgModeler installation (not the new beta version):
- Open your existing split model in the current version
- Save it as a single
.dbmfile - Install 1.2.0-beta1
- Open the saved
.dbmfile - Re-save it as a split model using the split model button
Alternatively, you can use pgmodeler-cli for migration:
- Backup your original
.sdbmfile - Run:
pgmodeler-cli -ri -if /path/to/splitmodel/file.sdbm(attention! this overwrites the original) - Edit the backed-up
.sdbmfile, removing all<object>tags while preserving the XML header<?xml ... ?>and<dbmodel>tags - Save this modified file as
metadata.xmlin the same directory as the new.sdbm
Both methods will successfully convert your split model to the new format while preserving all model data and relationships.
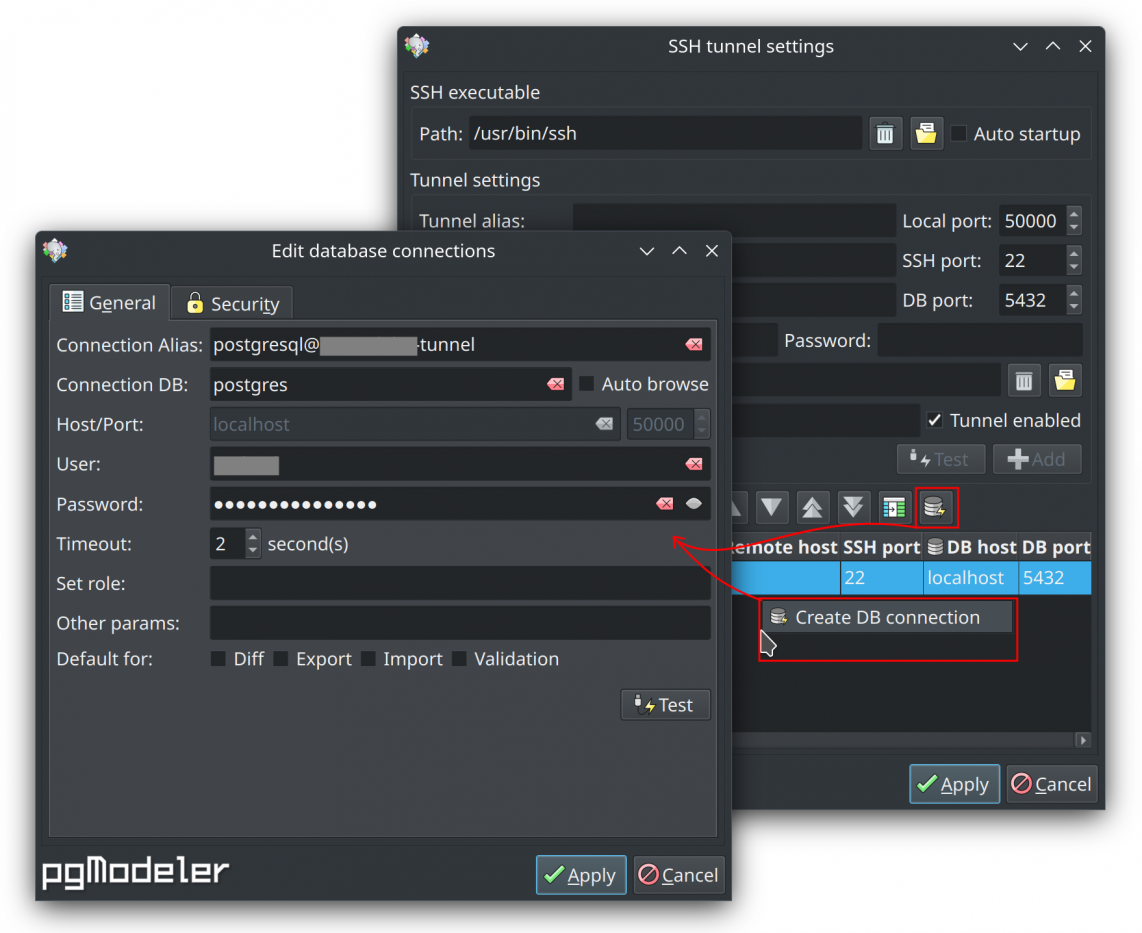
SSH Tunnel plugin enhancements
The SSH tunnel plugin in pgModeler Plus has been refined to create a more seamless workflow when establishing database connections through secure tunnels. Once you've successfully configured your SSH tunnel settings, the plugin now offers a direct path to set up your database connection without repetitive configurations. Simply right-click on any selected tunnel in the configuration grid or use the dedicated connection button ![]() , and the system will automatically generate a pre-configured connection for you.
, and the system will automatically generate a pre-configured connection for you.
You'll notice the connection form locks the host and port fields - this is because these parameters are already managed by the SSH tunnel, which creates a secure local port forwarding all traffic to your remote database server. This design not only prevents configuration errors but also reinforces security by ensuring all connections properly route through the encrypted tunnel. All you need to provide are the specific database name you want to access and your authentication credentials.
Removal of the support for Qt 6.2 and 6.3
The support for Qt versions 6.2 and 6.3 was removed. This was part of the codebase refactoring for simplified maintenance. Using such old versions of the framework was forcing the use of lots of conditional compilation instructions (the famous C/C++ macros). This approach tends to make the code hard to read and maintain. So, since Qt 6.2 and 6.3 official upstream support has ended, I decided to make the code compliant with newer framework versions. So, to be more precise, pgModeler now builds mandatorily on Qt 6.4.x and above.
Miscellaneous
- Added support for PostgreSQL 17.
- Improved the reverse engineering so columns can also be imported using the option "Import to the working model" in the database import form.
- Graphical objects added to the canvas area will now blink, and the viewport will center on them to indicate to the user where they were put.
- Adjusted pgmodeler-cli to raise errors when the ignore export error options are used in transactional export mode.
- Minor adjustment in diff form by making transactional mode mutually exclusive with the ignore export errors option.
- Minor fix in the file selector widget that was not applying correctly the palette colors in the line edit field.
- Minor fix in extensions creation/loading processes by ignoring duplicated schemas and using the ones already available in the model.
- Fixed a bug in the data dictionary generation for views.
- Fixed a bug in the SQL generation of the database model SQL related to an unknown database attribute.
- Fixed a bug when importing composite types having attributes using arrays of other user-defined types.
- Fixed a bug when displaying the source, in Database Explorer, of a composite type that has one or more attributes referencing user-defined types.
- Fixed a bug that was generating errors when running catalog queries of some objects in older versions of PostgreSQL.
- The model objects widget now accepts an Alt + click over a graphical object, highlighting it in the design view.
- Redundant search/replace instances all over the tool were removed due to the integrated search/replace widget in the source code editor.
- The extension editing form now properly supports custom schema names in data types.
- The database import process and the database model itself have been refactored for more reliable handling of extension-owned objects using the new extension object structure.
- The comparison operations in the diff process have been optimized to filter system objects correctly.
- The function behavior type was simplified by dropping the STRICT type since it has the same semantics as RETURNS NULL ON NULL INPUT.
- The database import form, when in debug mode, will remain open so the user can inspect the commands and objects created during the process.
- Fixed some crashes during diff operations on extension-created tables.
- Fixed the importing of columns using arrays of user-defined types.
- Fixed the time zone persistence on the timestamp data type.
- Removed false-positive diffs for functions with comments or STRICT behavior.
- Fixed reverse engineering of uppercase type names.
- When the export, import, and diff processes finish, the taskbar blinks when the window is not visible.
- Minor adjustment in the layers configuration widget to accept Enter/Return to apply settings.
- Fixed some shortcut conflicts in the main window.
- Minor fix in the "Open relationship" action in the design view.
- Fixed the index catalog queries when using pgModeler in compatibility mode (PG 9.x).
- Added support for displaying FK's update/delete actions in the data dictionary.
- The file selection dialog now starts on the user's home by default and saves the last accessed directory, using it the next time it is opened.
- Minor bug fix in code generation of tablespace, database, and user mapping objects.
- Minor fix in the object search feature when searching by source/referenced constraint columns.
- Minor fix in objects' grids to allow sorting the "ID" column as an integer value.
- Fixed a bug in the function editing form that was not resetting "SETOF" flag when changing the return mode to "Table".
- Fixed a malformed markdown code when a table or view had a comment.
- Fixed a bug in the diff process that was ignoring changes in columns.
- Fixed a crash in the database import process when destroying detached inherited columns.
- Fixed a bug in the database import that was crashing the application while trying to retrieve user mapping comments.
- Fixed a bug in the index object that was preventing the removal of included columns.
- The restriction of specifying OUT parameters in procedures was removed in compliance with newer PostgreSQL versions.
- Added support for the options check_option, security_invoker, and security_barrier in views.
- The syntax highlighting feature was completely refactored, being now more precise and the configuration files simpler.
- Minor fix in pgmodeler-cli in such a way as to warn about invalid changelog entries, avoiding aborting the entire model fix process.
- Fixed a bug in the reverse engineering feature that was not retrieving comments of sequences, causing false positives to be generated in the diff process.
Let's support pgModeler?
If you like the work being done to create a quality database design tool, please become our sponsor on GitHub. Any open-source project needs financial support to keep the development alive, which is not different from pgModeler. Go ahead, be a supporter in one of the offered sponsor tiers, and receive rewards for being a friend of an open-source project! :D
Please consider reporting any bugs or requesting new features through our GitHub repository. To stay updated with the latest project news and announcements, follow us on social media (X, Mastodon, Bluesky) or join our Telegram channel @pgmodeler.
With the feeling of accomplished mission, I want to thank everyone who uses and supports pgModeler over the years, either financially or by spreading the word about it! This tool wouldn't be what it is today if it weren't for the community around it! I'm really happy and grateful to see the fruit of my dream and hard work being praised around the world! :)
From now on, I'll start to organize some ideas for pgModeler 2.0 and start working on this next major release soon. I'm really excited to put my hands on this next challenge since there are a lot of things that I want to implement to make pgModeler a remarkable tool! That being said, for pgModeler 1.2.x, I'll release bug fixes from time to time, but new features will be postponed to 2.0.
Until next time! ;)
Add new comment