pgModeler grown up a lot since 0.9.0 with the introduction of crow's foot notation in 0.9.1-alpha, the addition of row level security support, identity columns, multiple relationships for the same table pair in 0.9.1-beta and many other improvements and fixes during the 0.9.1 development like detailed here. The development of the last stage of 0.9.1 was only to fix things introduced in alpha and beta releases and add few things here and there. Being said that, let's talk a bit about them...
Improved Command Line Interface
The majority of new features is related to the CLI which received the ability to import and diff databases which can make it even better to integrate to automated deployment processess or run quick tasks over models or databases without the need to open pgModeler's GUI. One important thing to note is that almost all of its options were refactored which means that if you're using the CLI in some of your deployment scripts you should review and fix them with the proper options. Below a snapshot of the CLI's menu expanded.
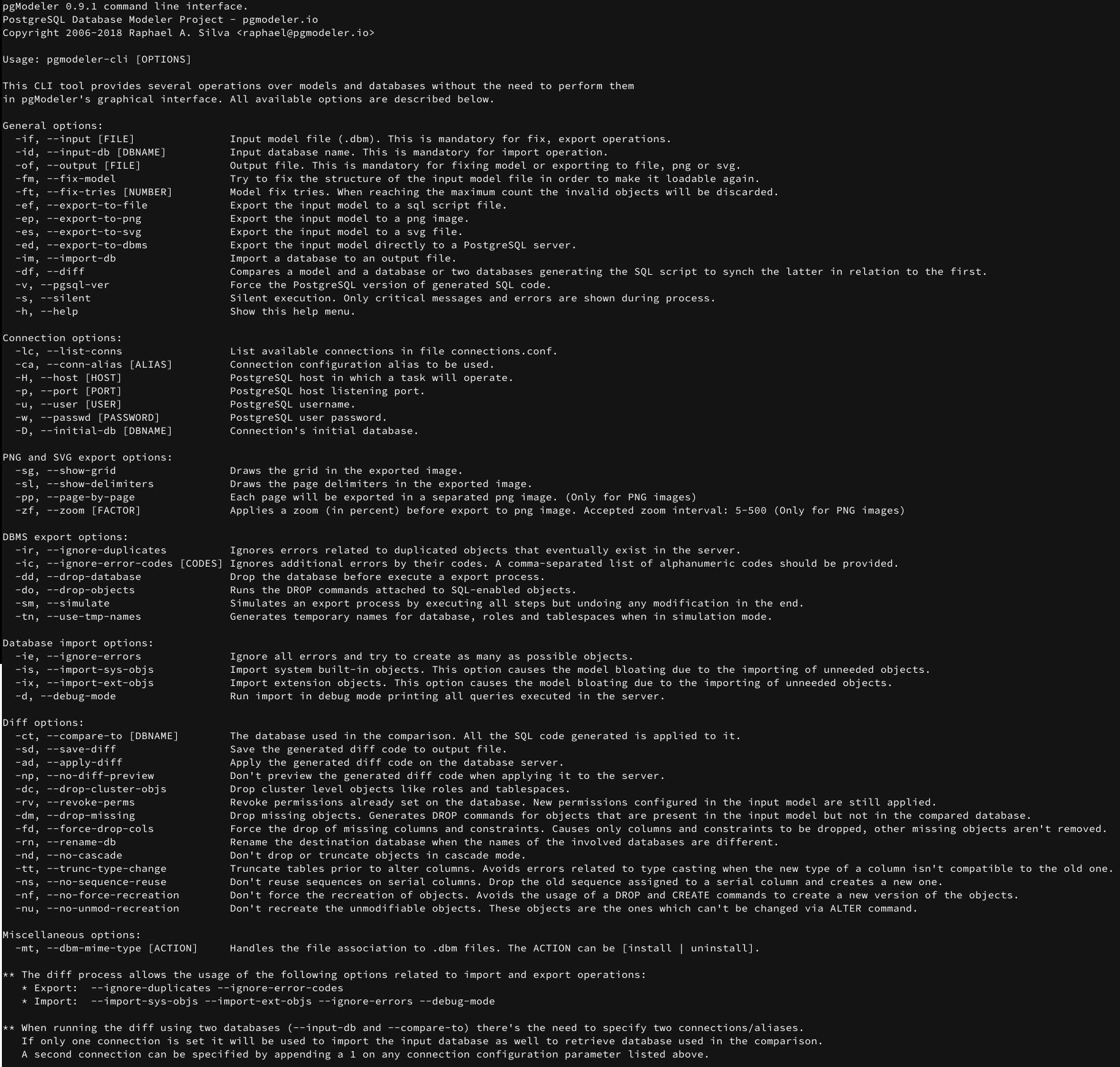
There're two new sections now: Database import options and Diff options. The options of both sections are used when the main operation of the CLI is set to import through--import-db or diff via --diff. There's no secret here, in the CLI the settings of these operations are the same as the ones presented on their respective dialogs at the GUI.
All the parameters are self explanatory (I hope!) but, in order to clarify, if you are willing to use the CLI to import a database you can run:
pgmodeler-cli --import-db [dbname] --output [outputfile.dbm] --conn-alias [alias]
In the command above [dbname] is the database that you want to import and [outputfile.dbm] is the name of the file in which all imported objects will be saved. The connection alias is the identification of the connection to be used to connect to the server. The available connections (read from the configuration file connections.conf) can be checked using the option --list-conns. Optionally, you can specify custom connection parameters instead of using pre-configured connections, just check the other options in Connections options section.
Now for the diff operation an example of command can be:
pgmodeler-cli --diff --input [dbmodel.dbm] --compare-to [dbname] --conn-alias [alias] --apply-diff
The command line above indicates that the diff process should take the database model stored in the file [dbmodel.dbm] and compare it against the database [dbname] which can be reached through the connection identified by [alias] applying the resulting diff code to the to very same database [dbname]. There is a second form to issue a diff command to pgModeler's CLI that indicates to the process to compare two databases instead of a model file and a database. The mentioned command can be similar to:
pgmodeler-cli --diff --input-db [inputdb] --compare-to [dbname] --conn-alias [alias] --apply-diff
The command above, compares two databases living in the same server. Note that we've replaced the --input parameter of the previous command by --input-db. In order to compare two databases which live in two different servers the user should run the CLI like this:
pgmodeler-cli --diff --input-db [inputdb] --compare-to [dbname] --conn-alias [alias] --conn-alias1 [alias1] --apply-diff
Note the usage of an addition connection alias at the end of the command. This indicates to pgModeler to consider the [alias] as the connection from where to import the input database [inputdb] and the [alias1] as the connection from where to import the database used in the comparison [dbname] as well where to apply the diff code generated in the process.
Talking about the generated diff code, optionally, instead of applying the code directly to the database/server using --apply-diff the user can save the code in a SQL script for later usage by replacing the last parameter in the commands above by --save-diff --output [script.sql]. By default, when using the --apply-diff, for security reasons the user should review the diff code to be applied and confirm it at the end before start running the generated code against the server. You can disable the diff code preview and run any generated code without confirm and for your own risk by using --no-diff-preview option. If you're bold enough to run the diff in that way make sure to have a backup first! :)
Using PostGiS types without the extension? The validation will help you!
Attending to some requests, pgModeler now creates the postgis extension in the presence of any table using its spatial types. How this is done? First, take a look in the screenshot below.
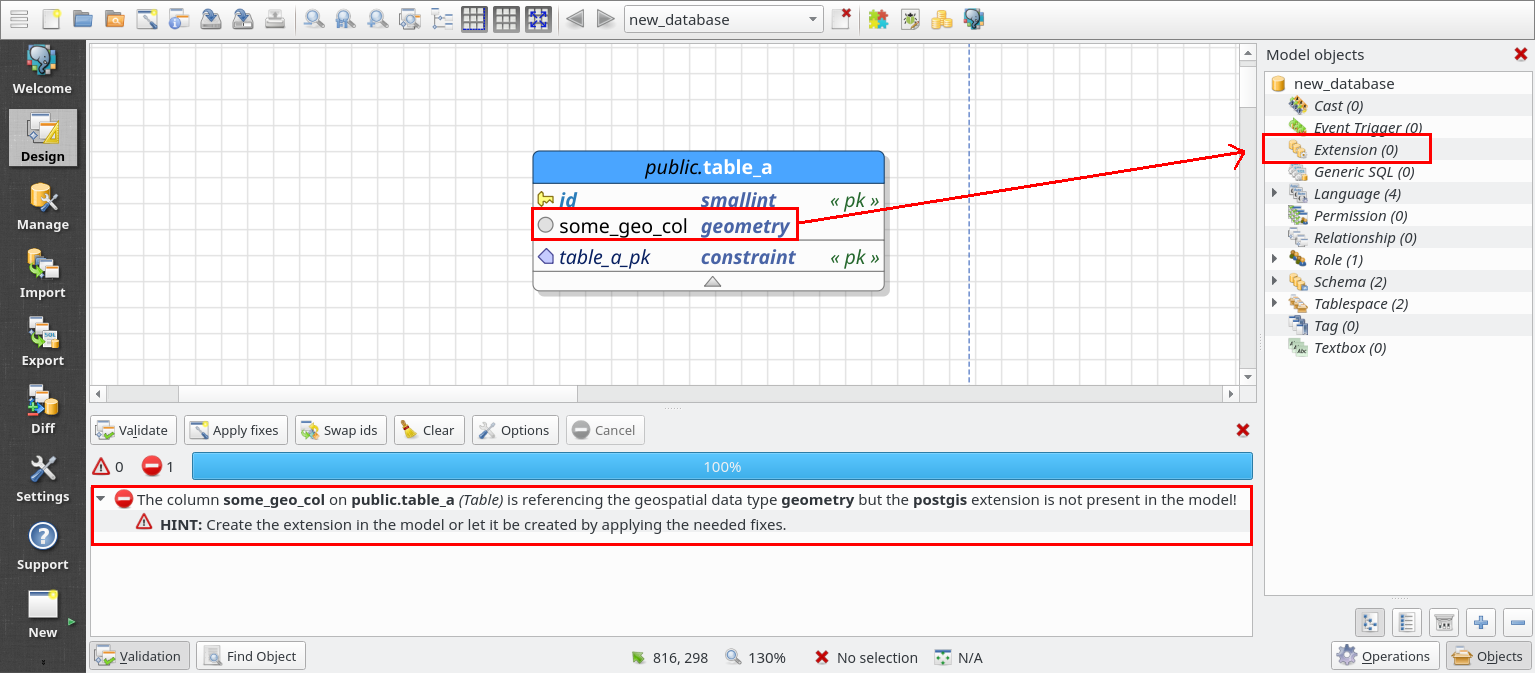
The simple model above has just one table with two columns, being one named some_geo_col of the type geometry which is a PostGiS data type. In previous releases the user needed to create the extension postgis manually before start using the tool's built in spatial types. Not doing that could cause the creation of a broken SQL code this because the validator couldn't detect the dependency of the spatial types used in the model and the missing extension. Now, pgModeler is a bit more smarter and points out the broken dependency suggesting ways to fix it (see the bottom portion of the image above). You can keep creating the extension manually or use the Apply fixes action in the validator in order to allow pgModeler create it for you.
One important thing to note is that once created by the validator the postgis extension will not be deleted in a next round of validation if no table references the extension. The user is the responsible to drop it. Maybe an improvement for the future? Leave your thoughts in the comments.
Improved command execution
Some important improvements were done in the overall performance of the SQL tool. The query execution and results displaying are a lot better now being quicker and less eager in terms of memory consumption avoiding crashes when querying large tables. To give you an idea, in previous releases, pgModeler could crash by running queries that could return less than 50K rows depending on the amount of memory of the user's machine. Now, the user is able to fetch millions of rows without crashing the application, of course, this still depends on the amount of memory available, but the query execution is now more reliable in terms of stability. There's still a missing feature that is scheduled to the next major release (0.9.2). The feature in question is the asynchronous query execution which will enable the user to stop the query execution if it takes to long to run.
Miscellaneous changes & fixes
There are other changes and fixes like another patch that fixes the resizing of dialogs in HiDPI/Retina displays. Several reverse engineering bugs were fixes and now databases are imported more precisely compared to previous releases. A bug that seemed to happen only on macOS while dealing with large models is finally fixed and was related to some running threads messing around with the main process avoiding it to correctly save the model and causing hang ups sometimes. Lastly, a small improvement on the source code input fields was done and now it enables the user to select lines of code by clicking and dragging over the line numbers aside of any the field. All the changes of this release can be seen at CHANGELOG.md.
That's it! Now I'm gonna to slow down the development just a bit in order to create the online documentation section in the project's site promised months ago. Also, as you may know, I'm gonna to participate the PgConf.Brasil 2018 and I need to prepare some materials to make a presentation in the event, thus, I need to sacrifice the time spent on coding pgModeler.
Talking about that event, the organization staff is looking for sponsors and if you or your enterprise has financial resources to donate, please, do it! This is quite important to make PostgreSQL and its ecosystem even more visible in Brazil and South America! See details here. This project embraces the event and is a sponsor too! ;)
See you next time!
lyun
July 10, 2018 at 21:13:25
Does partition table support?
Raphael Araújo e Silva
July 24, 2018 at 15:44:54
Hi! The partion table support is planned to be included in the development of 0.9.2.
lyun
July 24, 2018 at 20:36:57
I'll wait. :D
Mike M.
August 2, 2018 at 10:45:20
Does 0.9.1 have support for doing database diff between two PostgreSQL 10 databases? I'm currently using 0.9.0 and the diff works for 9.6, but upgraded my dev regions to 10 and am now looking for a diffing solution.
Raphael Araújo e Silva
August 3, 2018 at 13:01:37
Hi Mike!
Yes, pgModeler 0.9.1 now supports PostgreSQL 10 and you can do the diff.
Thanks
Mike M
August 3, 2018 at 13:23:04
Thanks!
Add new comment