I'm really proud to bring the crow's foot notation to pgModeler. It's not secret that this is an old request but since I was focused on make the tool more stable this feature was left in standby until I had the opportunity to start its development. Finally, I could put my hands on it after the release of 0.9.0 in September and now I present you the first version of the notation which notably improves the model's readability.
Before I start to describe the key changes of the 0.9.1-alpha, I would like to thank all the community that has formed around pgModeler. In every email or tweet that I receive be it a compliment, criticism or suggestion, makes me more motivated to continue to work on this project which started from a humble idea and now is almost 12 years old and has an enormous acceptance from all over the world. This project is what it is today because of all the collaboration and exchange of ideas made by everybody! THANK YOU SO MUCH!
Well, without no more delay let's see what this release brings in fact...
** Crow's foot notation support **
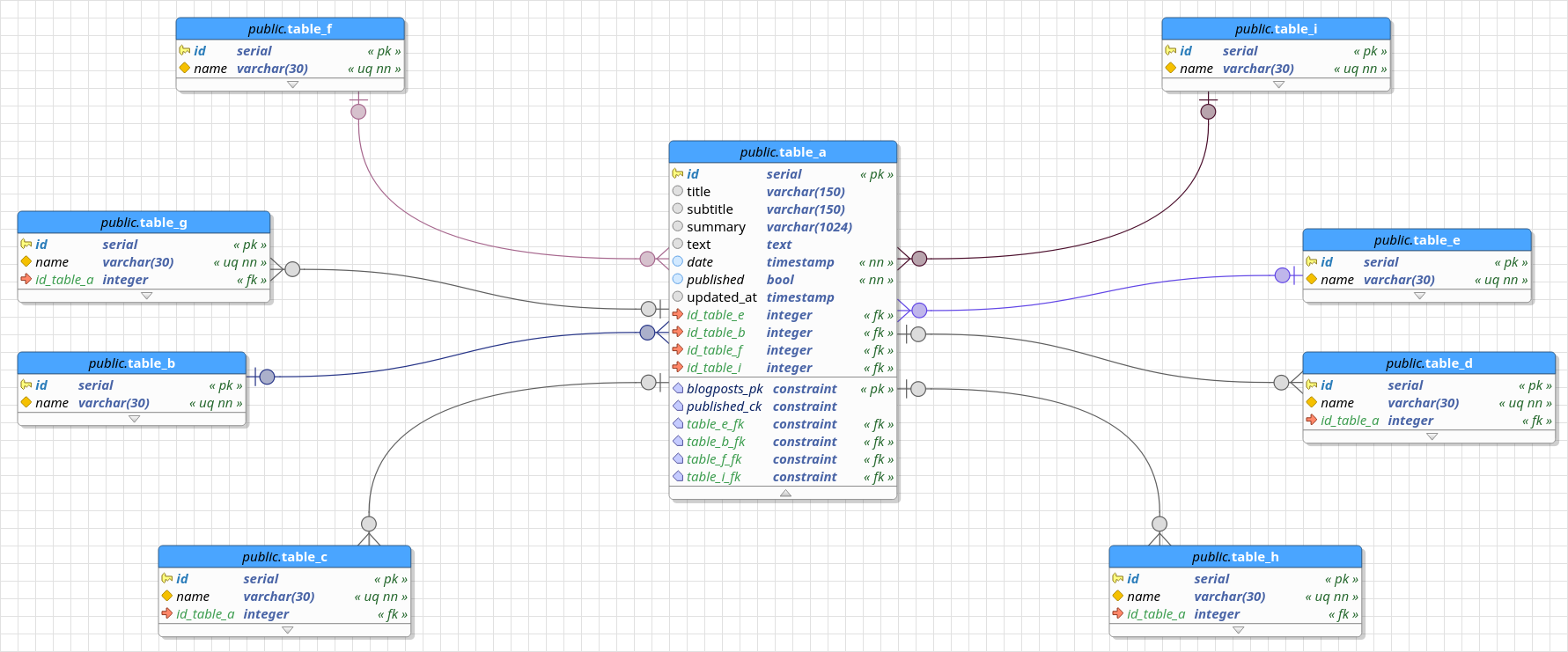
First thing to metion is that the new notation does not affects the way the SQL code is generated from relationships. Using crow's foot or classical notation the resulting code wil be exactly the same in both forms. The advantage of the crow's foot notation over the classical one is the readability. See for yourself...

Notice the difference and how we can understand the semantics of each relationship on the left more quickly compared to the ones on the right? This because the crow's foot has specific descriptors for each relationship (one to one, one to many, many to many). On the other hand, the classical notation relies on labels to describe cardinalities on the relationships which can be more difficult to understand, mainly for begginers.
Like any other feature in pgModeler, both notations are not perfect and have their limitations which lies in the lack of ability to handle some cardinality combinations. The relationships not supported in this case are: one-to-one where both tables are mandatory; one-to-many where the table at "many" side is mandatory; many-to-many where one of the entities or both are optional. The table below gives an idea of what is and isn't supported in terms of cardinality combination.
| One to one | One to many | Many to many | |
|---|---|---|---|
| A mandatory, B optional | O | O | - |
| A optional, B mandatory | O | - | - |
| Both entities optional | O | O | - |
| Both entities mandatory | - | - | O |
The introduction of crow's foot notation led to the enhancement on the relationships connection modes as well the relationship settings tab at main settings form (see below). Now, pgModeler counts with four different modes to link tables through the relationships: crow's foot notation, connect tables by their edges, connect foreign keys to primary keys and connect tables by their center points. The last three modes automatically enable the classical ER notation. In order to not extend this post too much you can see how each mode works by clicking the hint button (?) aside of the respective radio button in the form.

** Scattered schemas arrangement **
This new objects arrangement method will basically place tables in random positions within their respective schemas and then scattering the schemas themselves over the canvas area. Albeit being a random position generator the algorithm will try the most to avoid tables and schemas collisions/overlaps by detecting if the bounding rectangles of the mentioned objects intercept somehow. Once detected some collision the process will fix the colliding objects positions until no more intersections are detected. Depending on the size of the model, the process may take some seconds to complete. The method can be used, for instance, right after reverse engineering a database which contains several tables and schemas. Since the grid arrangement is the default when importing objects from a database, by using the scattered mode the user has a chance to sort the objects randomly and quickly without the need to move table per table to the desired location. A time consuming operation that turns to a time saving operation! Of course, the algorithm is still experimental and has its flaws. For instance, if the model is too big there'll be moments that constant overlaps or intersections will happen for the same set of objects thus pgModeler will stop to try repositioning these objects after a certain number of iterations avoiding the application hanging.

** Miscellaneous improvements **
Another addition done in pgModeler is the ability to toggle schemas' rectagles at once without the need to do it object per object. To do it, just right click a blank portion of the canvas area and use the Schemas rectangles action. About the bug fixes, most of them is related to the code generation, reverse engineering and diff process making these features more accurate and reliable. Finally, some small adjustments were done in the objects drawing and alignment in the design view due to the introduction of the crow's foot notation, minor changes were done as well in the manage view in order to enable the CSV buffer sharing between the database manipulation form and the sql execution pane (and vice-versa). The complete list of changes of this release is available in the CHANGELOG.md file.
I can't let to mention how is going our Mac Mini campaign. In the day this post was written, we gathered 72.47% of the total amount needed. If you still don't made your donation please help us to buy a Mac mini so the macOS version of pgModeler can be more polished. Remember, no matter the amount, helping out is the important point here! ;)
Don't forget: if you find any bug or have a suggestion contact us, all communication channels are open for inovation! :)
See you in the next release!
Nicolai
February 21, 2018 at 11:47:40
Hey, great news, when is your Crow's foot notation to be realeased?
Raphael Araújo e Silva
February 21, 2018 at 15:35:37
Hi Nicolai!
The Crow's foot notation is already released, since 0.9.1-alpha. You can toggle it at Settings > Relationship.
Add new comment