I proudly announce pgModeler 1.0.0!
A job of almost 400 days resulting in a bunch of improvements.
2023

The journey was really long, full of challenges that almost made me give up everything, but with the support from lots of people around the world, here we're, launching the long-awaited stable version of pgModeler 1.0.0! Since the early days of this project, seventeen years ago, I was anxious about this moment. This tool is the result of a dream of creating something really useful for the open-source community that I admire so much. I can't express in words how proud and joyful I'm about my hard work and the thousands of people that helped me so far. Thank you wholeheartedly to each one that reserved a bit of their time to make a contribution to this project. Your inestimable help was extremely important to keep this project alive and I hope to keep receiving all support needed to take pgModeler to levels even higher in the future! In resume, the development of pgModeler 1.0.0 took exactly, 398 days and 649 commits producing a total of 435 changes between new features, bug fixes, and improvements. In the UI, some parts were redesigned, new icons were created, and the long-requested dark theme support was added. In the code generation, the PostgreSQL 9.x support was dropped while PostgreSQL 15 was added. Also, the codebase was fully ported to Qt 6 and now pgModeler can take advantage of all improvements introduced by the framework. There were, of course, a bunch of bug fixes in practically all parts of the tool but the majority was applied to the reverse engineering and diff processes. The key changes of this version are detailed in this post, don't let to check it out!
I'm glad to annouce pgModeler 1.0.0-beta1!
Only one more development cycle to reach the stable version.
2022
This development iteration was mainly focused on code refactoring aiming for overall stability and code maintenance, but, as always, there were some minor fixes and changes in the user interface and in other core features. A new CSV parsing routine, improved reverse engineering, and minor adjustments in the design view are some of the changes in this release which are explained in the full post, don't miss it!
pgModeler 1.0.0-beta is finally here delivering important enhancements!
... and we're a step closer to the most awaited version ever: the stable 1.0.0!
2022
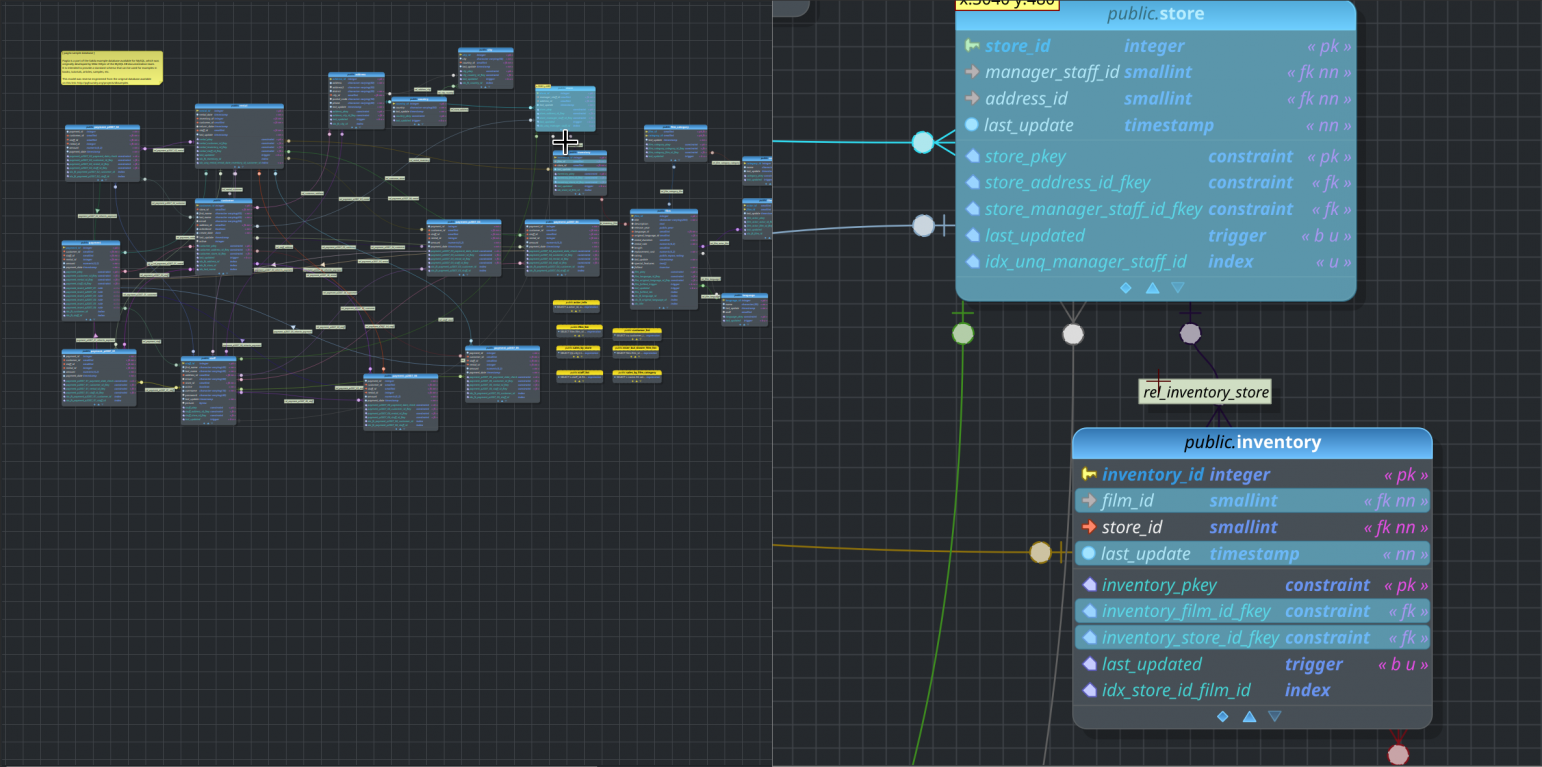
Following the path to the stable release, today I present to you pgModeler 1.0.0-beta. The main focus of this release is to remove the support for PostgreSQL 9.x which has not been maintained for over a year. This release also brings minor improvements in several parts of the tool. Now, the data dictionary displays information related to indexes, triggers, and sequences used in the tables, making the generated file much more complete from the documental point of view. Another improvement was the ability to generate SQL code split in the command line interface which allows generating SQL by objects in separate files. In the model design area, the magnifier tool has improved to allow better object interaction. As part of the continuous enhancement in the UI and usability, navigating through form fields using shortcuts and tab keys has been improved to be much more consistent and intuitive compared to previous versions. These and some other fixes and changes are detailed in the full post, don't miss it!
pgModeler 1.0.0-alpha1 is ready and waiting for you!
Another round of UI improvements and a major codebase change.
2022
Since the main focus of this release was to improve even more the UI, we had to work on the refactoring of the codebase to use Qt 6 which has lots of enhancements compared to the previous major version. So, after 2 months of work, pgModeler is now completely ported to Qt 6. So, attending to some requests, pgModeler received the ability to change the icon sizes to fit different screens in a better way. Still in the responsiveness subject and using the Qt 6 improved high DPI screens support, pgModeler allows the use of custom UI scale factors which adjust the entire user-interface rendering depending on the screen that the tool is running. Another enhancement that is worth mentioning here is that the columns/constraints propagation mechanism was completely rewritten which resulted in a noticeable performance gain and now solves an old problem of columns/constraints created by identifier relationships not being added or even disappearing in certain circumstances. More details on the full post.
pgModeler 1.0.0-alpha is finally here!
The beginning of a new phase in the project's development
2022
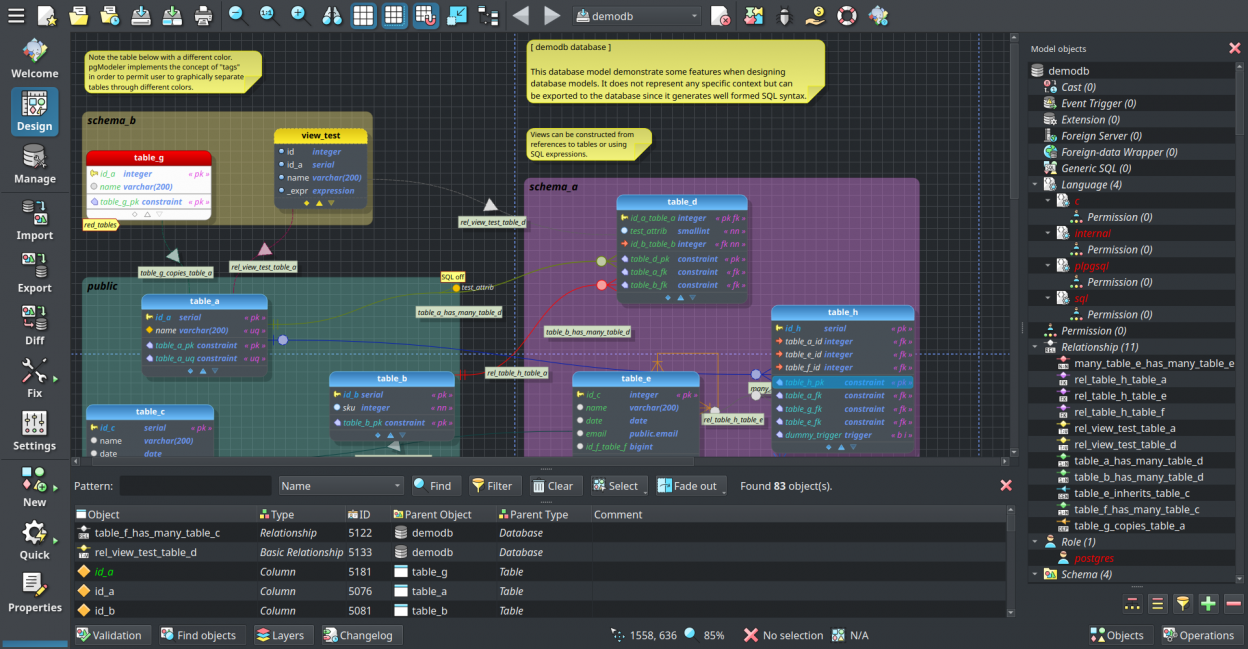
After four long months of working, we finally have the first alpha release of pgModeler 1.0! The main goal of this version was to boot up a series of deep improvements in the UI adding visual comfort while using the software. So that was done, this one brings redesigned UI elements and colors, a completely new icon set, and officially introduces the new project logo. As promised, pgModeler 1.0.0-alpha brings a responsive UI adapting the widget sizes and icons according to the screen's resolution. Also, we now have the support for color themes which can be toggled on-the-fly in the appearance settings. I'll explain more about what's new in the full post, don't miss it!
I proudly present you pgModeler 0.9.4!
Lots of improvements that close the series 0.9.x and boot up 1.x.
2021
It was quite a challenge to develop version 0.9.4 during the year 2021 but we finally made it, the last pgModeler of the series 0.9.x is ready! This one has a vast set of improvements over 0.9.3, being 51 new features, 104 enhancements, and 73 bug fixes that will make a big difference in the overall usage of the tool. In this post, I'll make a recap of all key features introduced by the alpha and beta versions and talk about the end of the development cycle of the series 0.9.x and my expectations on the development of pgModeler 1.0 in the next year.
pgModeler 0.9.4-beta1 is ready!
Only one more step to the stable release.
2021
In preparation for the next major pgModeler release, the goal of this version was to bring only improvements and fixes to what was implemented until 0.9.4-beta, and thus it was done. pgModeler 0.9.4-beta1 brings a few entries in its changelog since we didn't have serious bugs reported in the past two months. So, I decided to make some polishing in several portions of the tool as explained in this post.
pgModeler 0.9.4-alpha1 is out of the oven!
Another step towards pgModeler 1.0
2021
After two months of intense work, we finally made it! The last alpha release of 0.9.4 is ready bringing some important fixes, changes, and interesting new features. This version introduces the ability to export the database model in split SQL scripts either in GUI or CLI. Due to the introduction of a new syntax highlighting configuration, pgModeler now creates missing configuration files at startup avoiding breaking its execution, mainly when upgrading from an older release. The user is now able to drop databases quickly from the databases listing in the SQL tool without the need to browse them before performing the exclusion. Besides, a lot of changes were made in the files structure in preparation for pgModeler 1.0 that I'll start to develop right after 0.9.4. In this post I'll detail some key features of pgModeler 0.9.4-alpha1, so don't miss it!
pgModeler 0.9.3-alpha1 is out of the oven!
Extra PostgreSQL 12 support, reverse engineering filters and much more!
2020
After almost two months and keeping the spirit of polishing pgModeler's features during 0.9.3 development we're here to announce important fixes and some interesting new features in 0.9.3-alpha1. The first one is the capability of identifying and rendering relationships generated from foreign key constraints with the correct visual semantics. Also, pgModeler now allows the modification of objects generated by one-to-one and one-to-many relationships like columns and foreign keys constraints. Another great enhancement is the objects' filtering prior to the database reverse engineering, a handy feature if you constantly work on big databases by generating models from a subset of those databases. The tool also received support for some new PostgreSQL 12 features, now it is capable of handling generated columns while designing models, importing databases, and performing diffs. On the bug fixes side, some crashes were eliminated in different portions of the application. Also, relationships are now using correctly the provided global name patterns. Some other fixes were made on the system catalog queries and now running import and diff takes less time to complete. Don't miss the details on the full post!
The first alpha release of 0.9.3 is ready!
This time more focus on polishing than new features.
2020
After bringing some important improvements on 0.9.2 it's time to start another round of polishing all features available in pgModeler. This way, 0.9.3 development will be more focused on improvements of what already exists than the creation of new features. Of course, this will not prevent that some new functionality on the tool can be implemented, they will be just less prioritized. This release brings some requests related to database model design, which includes, bulk objects' renaming, multiselection on object finder and model objects widget and the introduction of the objects' Z-stack handling, a.k.a, "send to back" and "bring to front". Several bugs were fixed which were mainly related to reverse engineering and diff processes, but some other small bug fixes were provided over all parts of the tool. There were some important changes too, many of them related to code refactoring that the users will not notice but will improve code maintenance since it reflects on fast response on bug fixes and new features. The deployment processes were improved too, the code now compiles without problems in Qt 5.14.x as well in previous Qt versions. Additionally, the installers were almost all rewritten in order to provide a better experience for users who depend on binary packages. More details on the full post!