Hello there!
Here we are announcing another pgModeler release. This is always a joyful moment for me, especially, in these complicated times in which we all are living due to this damn pandemic that still persists! Well, in the past two months, I was working hard to polish what was released in 0.9.4-alpha as well as to bring some new features, not necessarily accessible directly by the user, but that will certainly improve the overall experience with pgModeler. Additionally to traditional improvements and bug fixes, I started to prepare the codebase for pgModeler 1.0 that I will start to develop as soon as the stable 0.9.4 is out. Said that, let's see in detail some key features of 0.9.4-alpha1!
Quickly drop databases
This is an old improvement that I wanted to implement but never found the proper way to do that, until now. This new release allows the user to drop databases quickly just by clicking the button ![]() aside a selected item in the database listing or hitting
aside a selected item in the database listing or hitting Ctrl + Shift + Del. In previous versions, the procedure to drop a database in SQL tool was to browse the database first and then to click the same icon at the top of the database browser widget. The old way to drop databases in GUI was kept in this release but it tends to disappear in the future since it is way more complicated than the new one introduced.
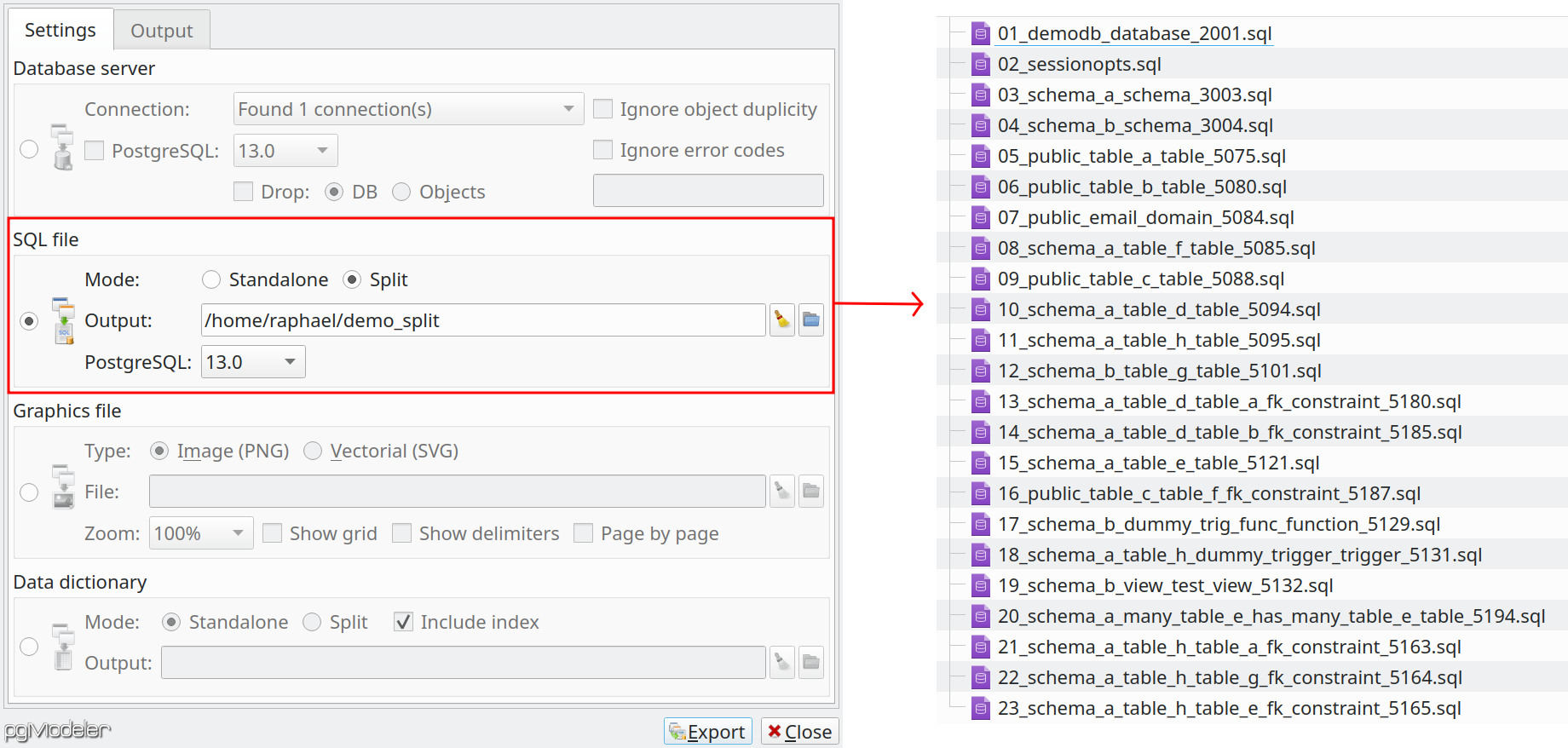
Exporting to split SQL files
Attending to requests, 0.9.4-alpha1 introduces split export mode. In this mode, instead of generating a single SQL file representing the entire database model, a file is created for each database object. Note that the files are named in such a way to represent the proper order of creation (see below), thus, running the scripts one after another will create the whole database like it was created from a single file. This mode can be useful for custom deployments processes where you need to create objects one by one in the database server while performing any other parallel task needed by your development tool. The pgModeler's command-line interface also supports this new mode, just provide the parameter -sp or --split while using the export operation--export-to-file.
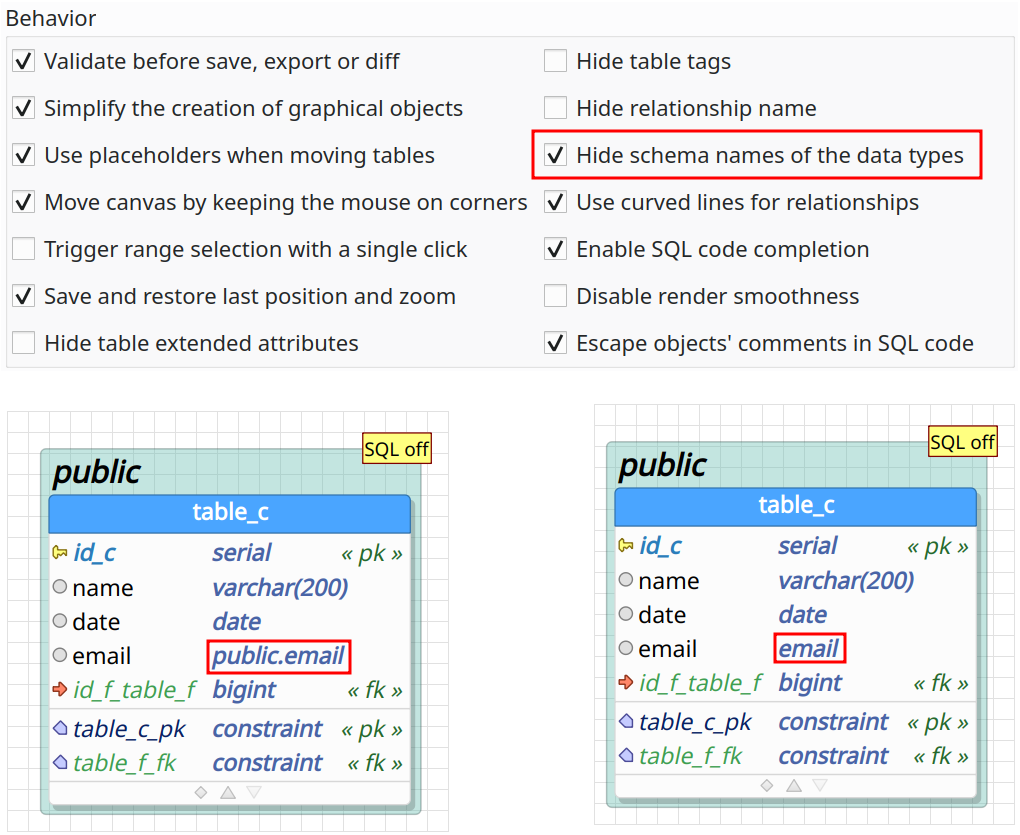
Hide schema names from data types
Another change brought by pgModeler 0.9.4-alpha1 is the improved user-defined data type handling. In the middle of these enhancements is the ability to toggle the displaying of schema names of user-defined data types used by table columns. This can be adjusted by the option Hide schema names of data types in the group Behavior on the general tab at pgModeler's settings. This is a convenient way to display your database model in a more compact way if you use lots of user-defined types. Note that toggling the schema names only affects the design view, the code generation and other portions of the tool still need to use schema-qualified user-defined data types to avoid conflicts.
pgModeler Schema Editor tool
Due to the need to constantly edit schema files for code generation test purposes, I decided to create my own mini-editor called pgModeler Schema Editor (pgmodeler-se). The idea to create the application pgmodeler-se came from the lack of native support for *.sch on my preferred editor (hello, Kate!). In fact, Kate can handle this type of file with some tweaks here and there but I found it more complicated than creating a small editor from scratch since I had everything I need in pgModeler's codebase.
With this auxiliary tool, an advanced user can manipulate the schema files stored in the schemas folder. You can, for example, change the default SQL/XML code formatting, add extra instructions to the generated code, validate the syntax of the documents, apply automatic indentation, and much more. The application also allows you to tweak the syntax highlighting files (SQL, XML, or SCH) either in the user's local storage or in the pgModeler's installation folder. Of course, this application is not for every user since it may break your pgModeler installation if some wrong edition is made on any file that it handles. So, use it with caution! :)
Here comes pgModeler 1.0!
It's no secret that, for a long time, I want to start to work on pgModeler 1.0. So, since pgModeler 0.9.4-alpha, I'm making small changes here and there to shape the codebase into the final form I want to 1.0. This time, I made some important changes in the folders in the source code root. The first change was to rename all the remaining icons from Portuguese to English and performing the needed changes in the source code. Some unused or outdated files were removed too.
The libraries subprojects were moved to the folder libs and some of them were renamed to give better semantics. The libpgmodeler now it's called libcore, libpgmodeler_ui was renamed to libgui, and libobjrenderer received the new name libcanvas. This rearrange was applied to executables subprojects as well. Now there's a dedicated subfolder called apps which store all executables subprojects, thus, the main executable subproject was renamed from main to pgmodeler, the crashhandler is now pgmodeler-ch, the command-line interface subproject main-cli was renamed to pgmodeler-cli, and the pgmodeler-se is the new executable subproject related to the pgModeler Schema Editor application.
Finally, the last change made in the source code root was to create a folder called assets and store in it all the files that are deployed with libraries and executables, for example, code schemas, language settings, configuration files, and database model samples. These changes don't affect you if you just compile and use pgModeler. But if you're a plug-in developer or a package maintainer, or even have a custom code running over pgModeler's code you may need to review your build process in order to check if something is broken after such changes.
Miscellaneous
Some other enhancements and fixes that worth to mention are:
-
The addition of new metacharacter to schema micro-language. The metacharacter
$hstranslates to hash character#,$psis for percentage sign%,$atdenotes@, and$dsmeans dollar sign$. -
Added the option
--forceto the mime type handling operation on the command-line tool. This option can be used in certain circumstances where the CLI can't determine if the file association is correctly installed/uninstalled. -
In the data manipulation form, the behavior of column click was changed. Now, the sorting operation over the column is triggered by holding control and clicking it. If the user clicks a column without holding the control key all the items on that column will be selected instead of performing a sorting.
-
The crash handler application and bug report form (inside GUI) was patched in such a way to capture the last modified model opened. Previously, the model captured was always the last one focused and not necessarily the one that caused the unexpected crash or bug on the tool, which could not help to identify the problems reported by the users.
-
The database import is in constant enhancement, this time a crash when importing inheritance relationships was eliminated. Additionally, the data types related to extensions are now being properly configured and associated with columns.
-
A malformed SQL code generation when configuring
timestamptzwas fixed. -
Fixed a bug that was causing all layers to be active even if there were some inactive (invisible) layers when adding a new one.
-
The command-line interface does not crash anymore when running the diff operation in which a database model is used as input.
There are many other fixes and you can check them in the file CHANGELOG.md. Anyway, I'll be here waiting for your feedback on this new release. Leave your thoughts in the comments sections that I'll gladly respond to them, and if you stumble on any bug or problem running pgModeler don't hesitate to ask for help at the GitHub issues page.
Enjoy pgModeler and until next time.
Take care! ;)
Add new comment