Oh boy, here we are five months later to announce the first alpha of the new minor version 1.1.0. During this time, I tried to focus on improving mainly the SQL tool and I succeeded in bringing a good set of features that will make this section of pgModeler more fun to work with. Of course, the other parts of the tool were not forgotten and some of them have received some patches, as I detail right below.
Enhanced SQL tool
By far, the SQL tool was the most worked component of pgModeler during this development iteration. Since the database modeling is working pretty well for quite some time, I decided to put into practice my desire to make the SQL tool more feature-complete. There are more things to be introduced and I'll try to release them until the stable 1.1.0 is ready, but for now, that's what we've got:
- Improved code completion: A long-awaited feature is finally arriving pgModeler: the code completion based on living database object names. From now on, in the SQL execution widget, will be possible to list schema, table (and column), and function names in the middle of the
INSERT,DELETE,TRUNCATE, andUPDATEcommands. This feature also considers table aliases and lists the correct columns. It is worth mentioning that this feature is still experimental despite the good results on different kinds of SQL commands. Anyway, this is another feature that will improve even more the overall experience when managing databases in the built-in SQL tool. Of course, like any other new feature, there are some limitations. For this one, as you can see in the video below, you have to always type the schema name first so pgModeler could search for the objects in the system catalogs. The code completion widget ignores completely the current session search path.
- Automatic concatenation characters removal: When pasting SQL code coming from external IDEs in SQL execution using
Ctrl+Shift+V, pgModeler will try to remove unneeded string concatenation characters (e.g." ' + .) in the clipboard text before inserting it into the input field. This is useful for quickly testing a SQL code written in other languages' source code using concatenated strings.
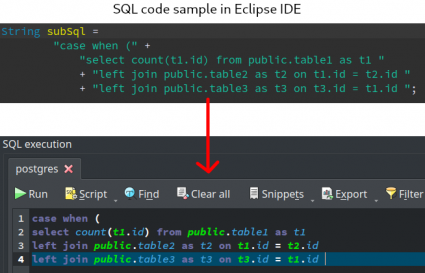
- Enclosing characters highlighting: In any field where it's possible to type SQL code, the characters
(), [], {}are now highlighted in order to indicate the correct balance of those characters avoiding syntax errors when running the typed commands. The feature also indicates unbalanced characters by changing the background to red.
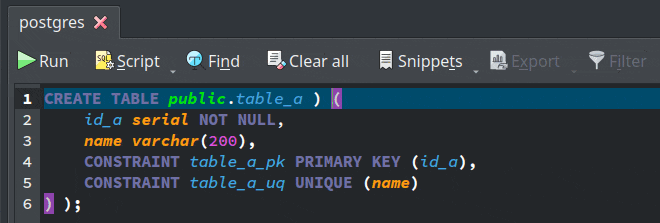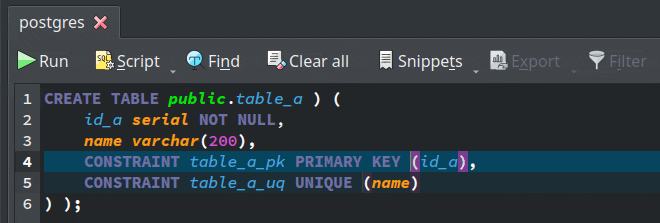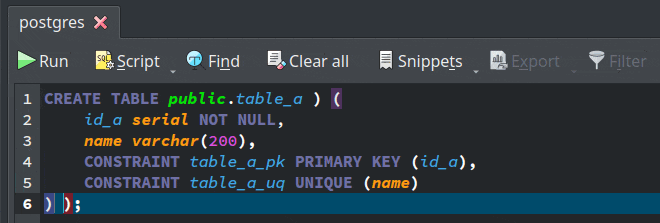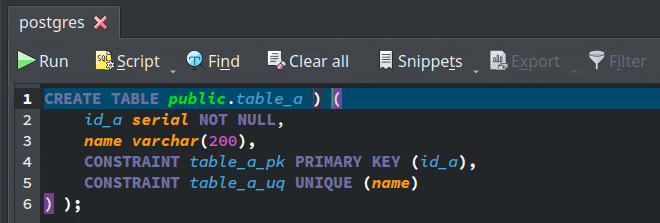
- Improved CSV support: The results of the DML commands executed in the SQL execution widget as well as the data displayed in the data manipulation form can be now exported to CSV format by activating the action
Export > CSV File.
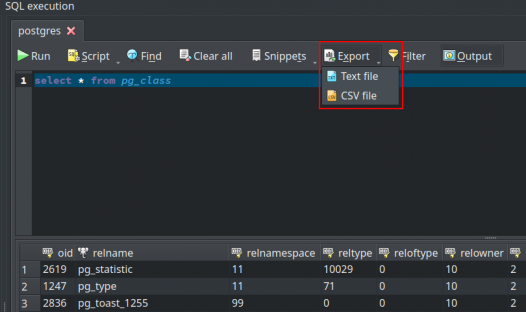
- Enable large data truncation in the results grid: In order to display large data (e.g.
bytea) in the results grid without degrading the performance an option was added to general settings that toggle the truncation of column data that exceeds a certain limit. The truncated data can be fully visualized by double click the desired cell in the result grid.
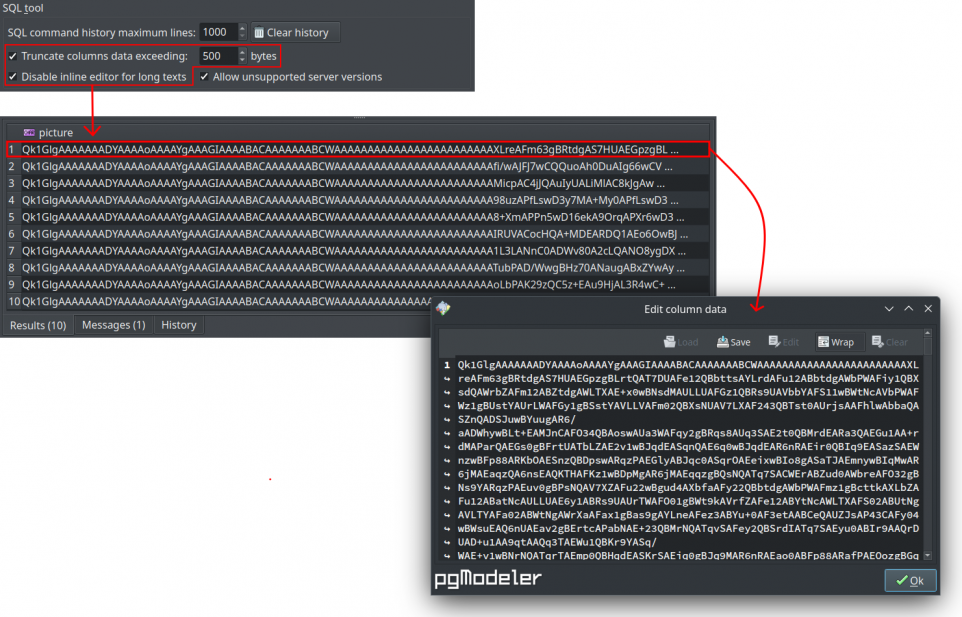
- Data type icons in data grid: This is a small aesthetical enhancement but it helps a lot to give users the idea of which data type a certain column has. Basically, an icon of the type category is displayed at the left of the column name. This change affects the result grids in SQL execution widget as well as the data manipulation form.
More UI improvements
This release also brings more UI improvements, adjusting those features introduced by 1.0.x or including new ones as described below:
- Improved UI color management: In 1.0.x, pgModeler couldn't correctly follow the system's color set (dark/light) forcing the user to manually adjust the color settings for the syntax highlight. Now, in 1.1.0-alpha, selecting
System defaultUI theme in Appearance settings makes pgModeler properly configure the UI element colors as well as the source code highlight settings according to the current system's color schema.
- Drag & drop support: pgModeler now supports the drag & drop of .dbm files selected in the file manager directly into the tool's main window to load models. You can drag and drop files into the Welcome or Design views which causes pgModeler to toggle the file loading mode taking as input files those held over the tool's window.
- Disable objects' shadows: Database object shadow element can be now deactivated in the general settings, at behavior options, giving an overall performance boost in heavy-populated models since fewer objects per scene need to be handled.
Bug fixes
Also, as part of the constant search for the overall tool's stability and reliability, almost twenty bugs were fixed, and below we highlight some key ones:
- Fixed a critical bug in pgmodeler-cli that was causing the generation of empty models when the input file had no roles configured.
- Fixed a bug in the database model that could lead to an "unknown exception caught" error.
- Fixed a bug in the CSV generation that was causing the creation of malformed CSV in some circumstances causing the initial table data corruption.
- Fixed some problems with comments when importing a database having the same OIDs for different types of objects.
- Fixed the diff process performed on legacy database versions.
Backup utility plugin
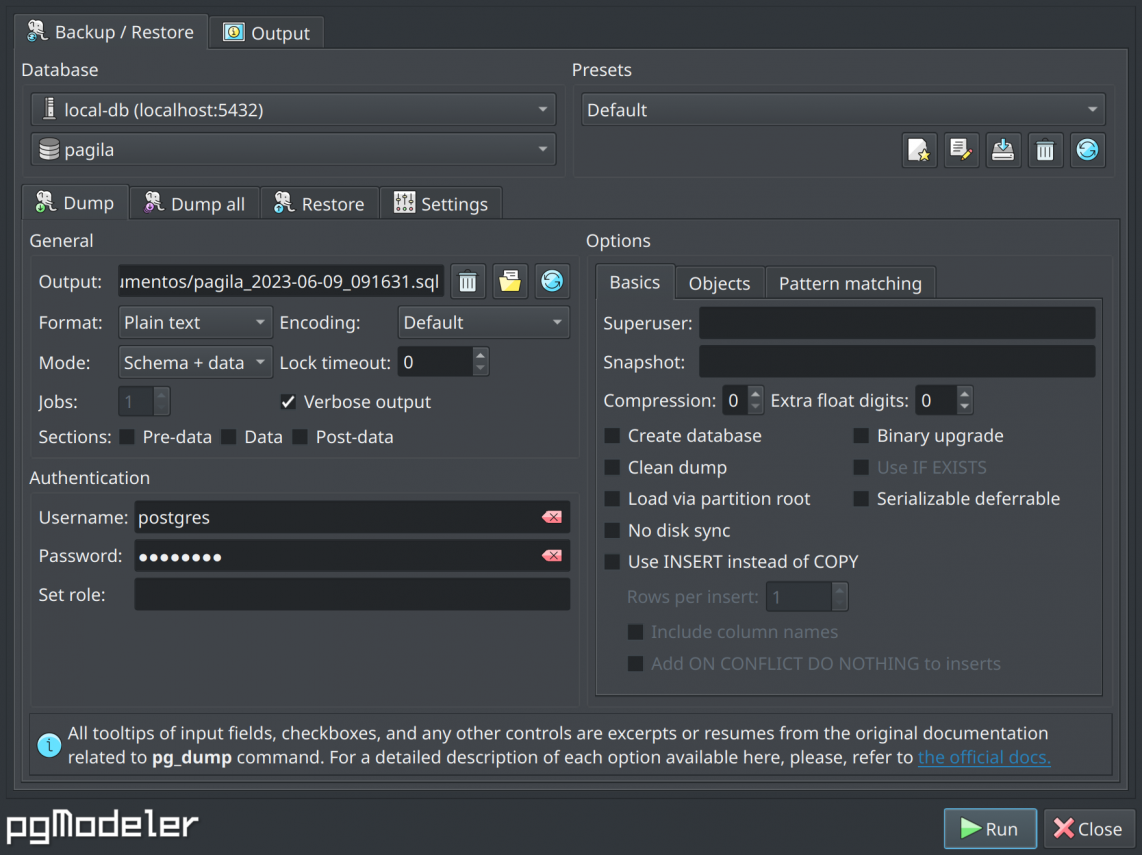
This version introduces the backup utility plugin, available in the paid version of the tool, which implements a user-friendly interface for the commands pg_dump, pg_dumpall, pg_restore and psql. This extra feature was developed mainly focused on attending to those users less comfortable with command-line tools, being possible to dump and restore databases without leaving pgModeler's GUI. Of course, advanced users are welcome to use the plugin and help to improve it!
In a nutshell, besides configuring the backup tools parameters with a simple form, it allows the creation of presets per backup tool for different needs, it also has some facilities that automate the backup file name generation by using a default backup folder and name patterns. Since the plugin reuses the configured connections information passing them to each backup utility command, make sure to use credentials that can log in to the server and perform a dump or restore or the processes will fail.
The image below shows the pg_dump section of the plugin. The options there are user-friendly labels for each command-line option so, in case of doubts, you can always refer the official PostgreSQL docs to obtain detailed information about them. Specifically for Dump and Dump all sections, selecting a connection and a database name in the Databasegroup at the top-left portion of the form, will trigger the automatic output filename generation according to the parameters defined in the Settings tab. If now the automatic name generation parameter is defined, then you have to manually specify the output filename.
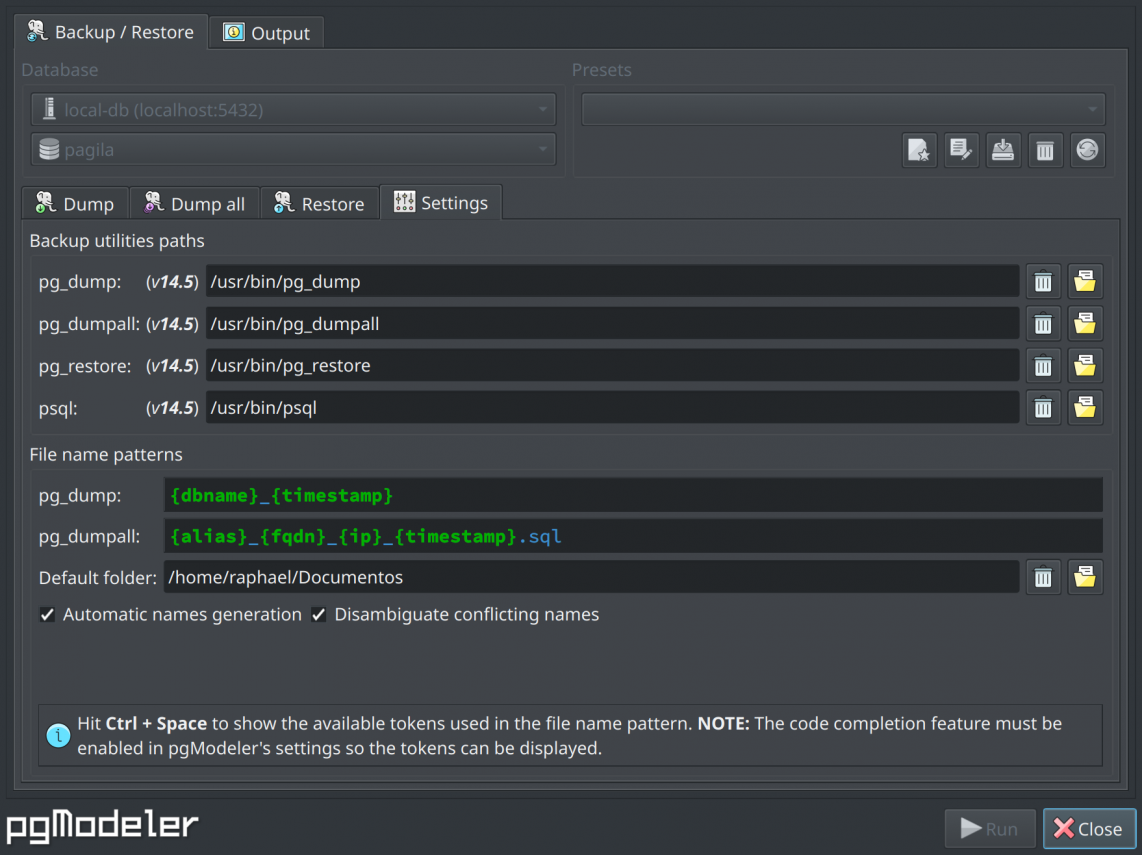
The backup plugin settings section is quite simple and demands almost no user interaction in a normal initialization. In the Backup utilities paths, the plugin tries to locate the needed PostgreSQL backup utilities and assign them to each selector. If one or more executables couldn't be found the related selector will display a warning sign so the user can fix the problem. In the File name patterns, is where the automatic name generation feature is configured. The first two fields, pg_dumpand pg_dumpall are the name patterns used in Dump and Dump all sections. In those two fields, hitting Ctrl+Space shows a popup with the available tokens used by the patterns to create the output file names. The Default folder selector is a valid path to a folder where all the backups will be saved. Finally, the Automatic names generation option toggles the whole process of generating a name based upon the options configured in the group, while the option Disambiguate conflicting names will avoid the generation of names that somehow may overwrite a backup file already preset in the output folder.
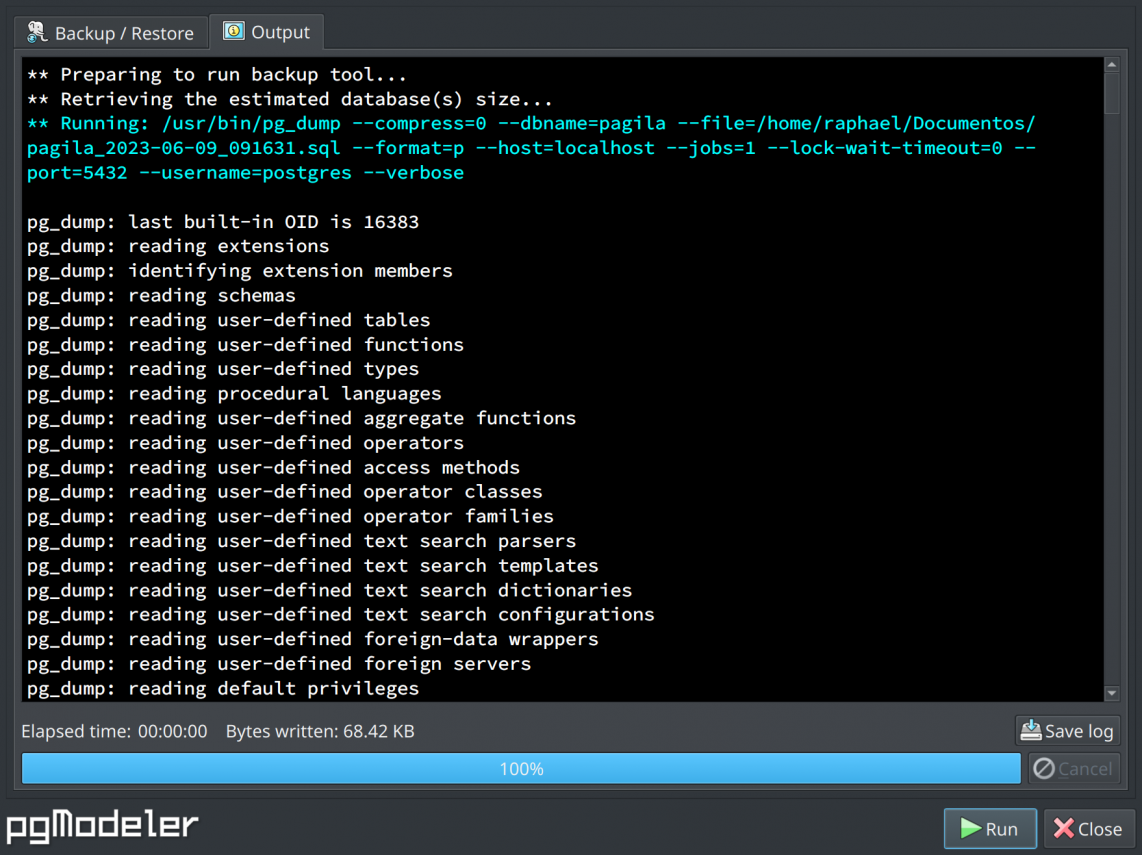
Once you have tweaked all the desired options in the backup utility tab, just hit Run to start the selected backup tool. Once started the process, all the output will be displayed in the Output tab like the image below.
Let's support this project!?
If you like the work that is being made to create a quality database design tool, please become our sponsor on GitHub. Any open-source project needs financial support to keep the development alive, and this is not different with pgModeler. Go ahead, be a supporter in one of the offered sponsor tiers, and receive rewards for being a friend of an open-source project! :D
In addition to GitHub Sponsors, there's an active campaign whose goal is to acquire a new Mac Mini with the new M2 chip... and we are almost there, with 70% of the total amount already received! So, if you are a macOS user and think pgModeler can be improved in that platform, please, consider supporting this campaign. Thanks in advance! ;)
Well, that's it! If you're interested in seeing the full list of changes in this version, please, take a look at the CHANGELOG.md file. Also, if possible, leave your thoughts about this new version in the comments section, and don't forget that any bug and feature request can be registered on GitHub. Also, follow pgModeler on Twitter or join the telegram channel @pgmodeler for fresh news about the project!
I hope you enjoy this new release. Until next time! ;)
Diego Moreano
September 23, 2023 at 00:53:45
An amazing product, I purchased a windows and mac version a year or so ago and is by far the best purchase in my long list.
Raphael Araújo e Silva
September 25, 2023 at 10:52:39
Thank you very much, Diego! :)
Add new comment