I'm glad to announce that we're close the finishing another development cycle. This first beta version of 0.9.2 brings some new features and fixes some bugs just to make pgModeler even better to work with. However, before start talking about the new pgModeler I would like to apologize for the delay on releasing it. On my plans this beta would have been released last month but lots of things happened to me that make me stay away from pgModeler for a considerable time in these last five (almost six) months. So, for now on, I hope I can hop back to the development speed I had before, bringing new versions on each 3 months. So... let's not waste more time and start to detail what's new in this version!
** Foreign data wrappers, foreign servers and user mappings **
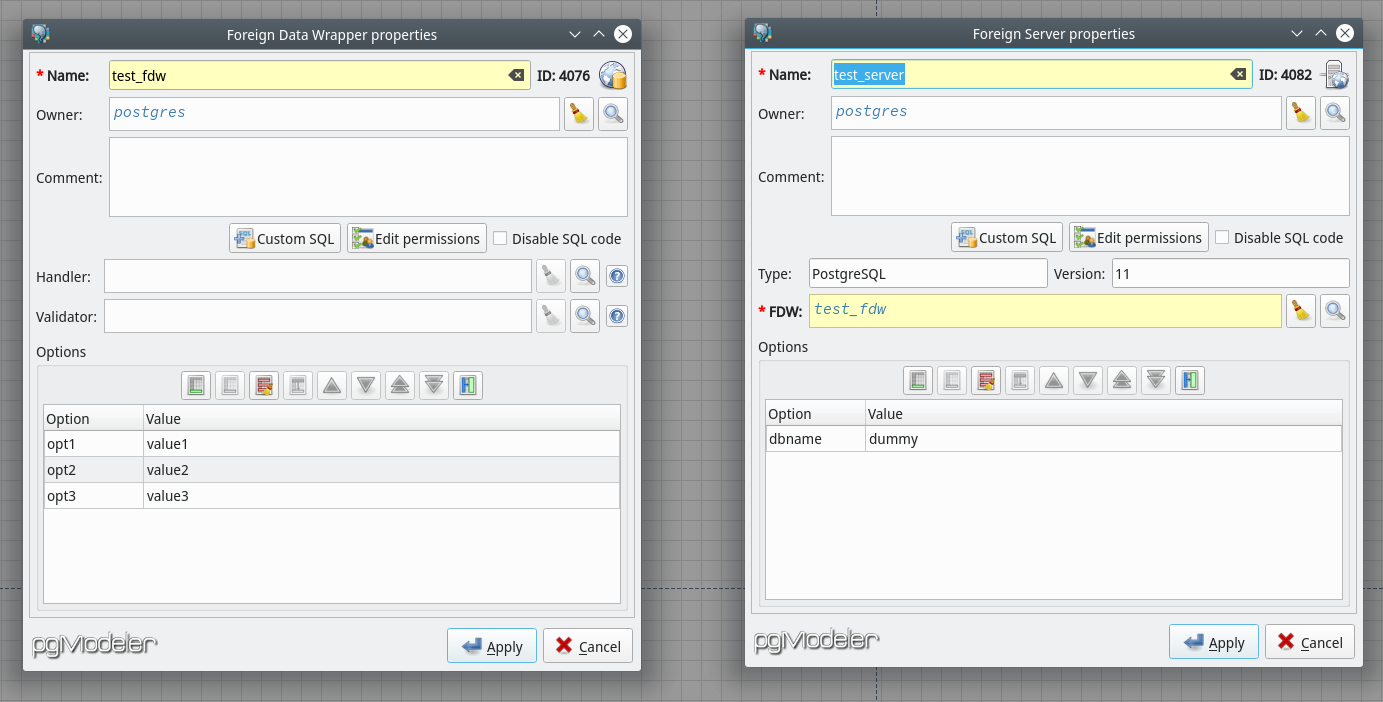
Three really useful objects on PostgreSQL are now fully supported by pgModeler: foreign data wrapper, foreign server and user mappings. With foreign data wrappers one can consume data from different data sources like CSV files, web services or even database servers from different vendors. Likewise PostgreSQL, foreign data wrappers aren't complicated to configure. See this object's editing form below. Of course, you have to check official docs to understand how this object works and how to implement custom data wrappers according to your needs.
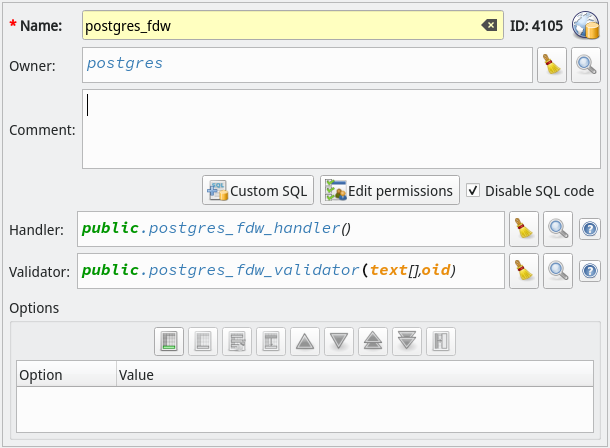
Foreign server encapsulates connection informations that a foreign data wrapper uses to access an external data resource. An user mapping, on the other hand, holds user-specific connection information used by a foreign server.
** Need to create foreign tables? Use generic SQL objects! **
Since this release doesn't bring foreign tables support I needed to implement a workaround while the implementation of that kind of objects isn't ready. This way, I've made generic SQL objects more powerful enabling them to store references to other objects so the code held by the generic SQL is automatically updated when some of the referenced objects change their code as well. Found it a bit confusing? Don't worry, let's see how it works with more details.
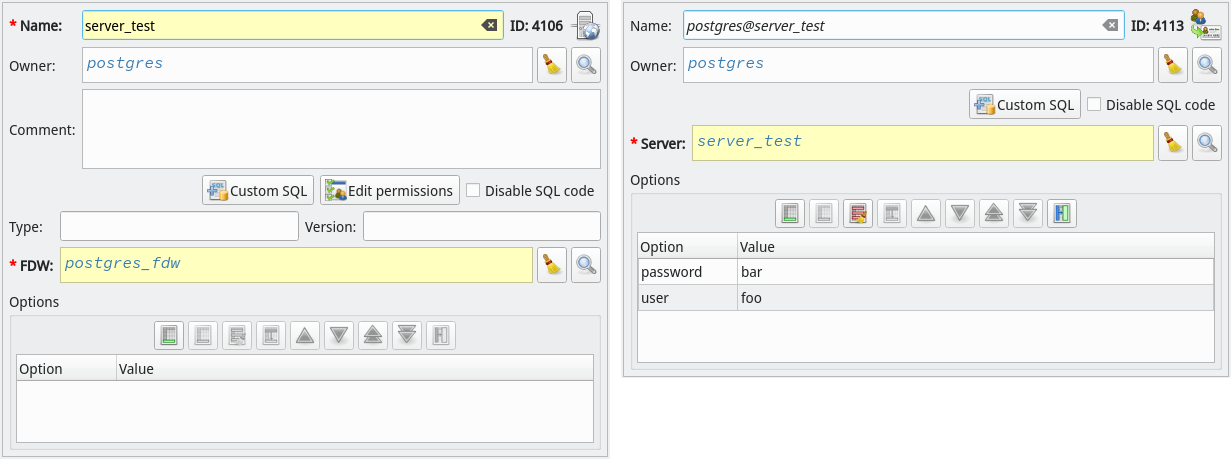
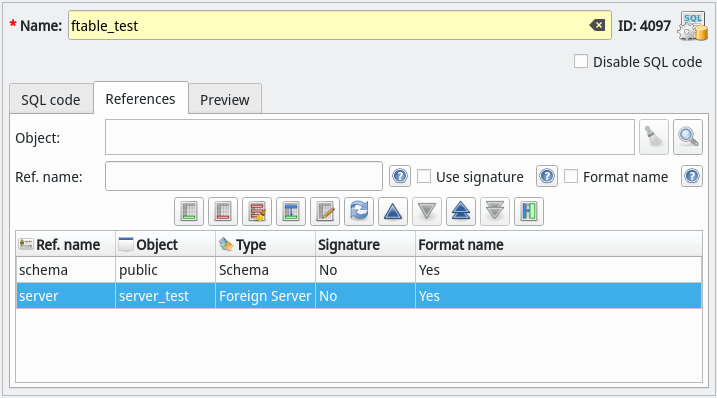
Let's suppose we want to create a foreign table named ftable_test. What we have to do is to use a generic SQL object to store the base definition of the desired object as examplified by the image below. In the sample code the special attributes {schema}, {name} and {server} are known as references. Except for {name}, they hold the names of the objects that are used as part of the foreign table's SQL code and they can be configured in the tab References as detailed in the next image. The attribute {name} has another special behavior that is to hold the name of the generic SQL object itself. In this case, it literally stores the value of the field Name of the object's editing form. This attribute exists as a convenience and allows you to change the name of the of the generated object just by changing a single field instead of change the base code definition.
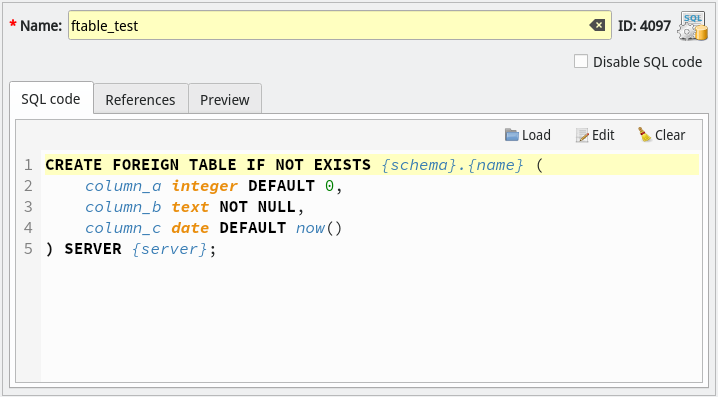
Now, talking about references, they are just simple variables which keep track of changes on the names of the referenced objects. In the image below we have defined schema as a reference to the schema public and server as a reference to the foreign server server_test, both objects previously defined on the database model. For each reference there're two options regarding the name usage and formatting: Use signature and Format name. The first one, when checked, indicates that the referenced object's signature must be used instead of its name. For objects like functions, casts, operators and some others the signature is slightly different from the name by including parameter data types and some other relevant information. The second option, when checked, indicates that the object's name (or signature when used) must be automatically double-quoted when there's the presence of special characters.
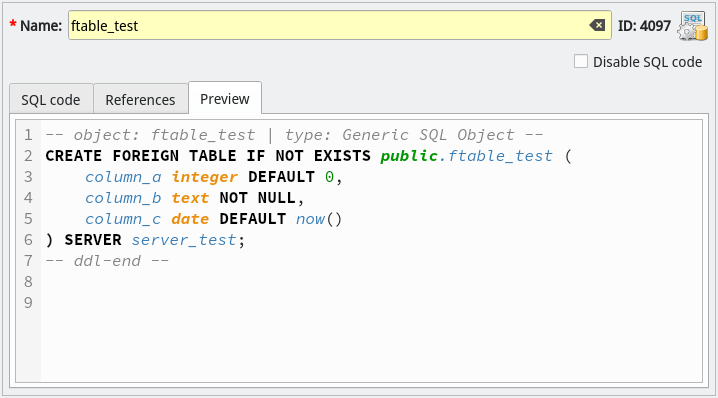
Finally, when you have everything configure, you can check on-the-fly how the code of the generic SQL object (in our example, the foreign table) will look like just by focusing the Preview tab. See how the references where replaced by their respective tracked objects' names. Pretty cool, huh!?
As any temporary workaround there's a sad thing on all this. The foreign table created through a generic SQL object can't be imported to a database model because pgModeler doesn't "know" this kind of object. This limitation applies to the diff process too. Said that, I hope in the next beta release we already have a preview of foreign table support on the tool. So, until there, that's the way we have to use foreign tables in pgModeler.
** Reduced verbosity on export, import and diff **
Attending to some requests, an, option was added to pgModeler which reduces the verbosity of the export, import and diff processes. By reducing the displaying of information elements on these processes' output less UI operations need to be performed and, as a consequence, it makes these processes run faster. When enabled this option causes only key info messages and errors to be displayed. This can benefit slow systems running pgModeler by saving some CPU usage. This option can be toggled in the general settings.
** Improved object searching **
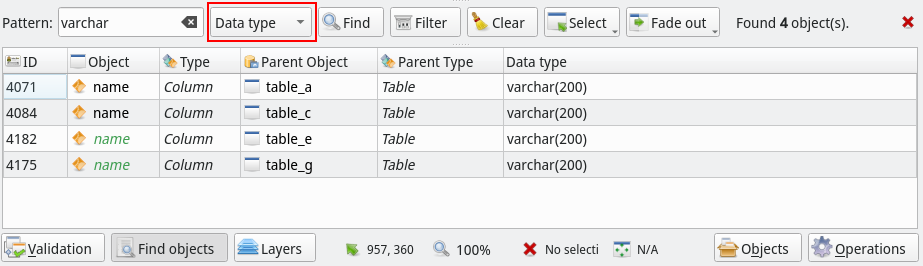
The object searching received an small but interesting improvement: the ability to search additional object's attributes. Now one can match a keyword against object's names, signature, comment, data type, schema, owner, tablespace and return type. If you need additional searchable attributes let me know by sending a feature request on GitHub.
** Miscellaneous changes and fixes **
This release also brings some miscellaneous changes and fixes that are worth to mention. The first improvement is the remodeling of the action New object in the canvas popup menu in order categorize object types diminishing the amount of items displayed on the screen. Currently, pgModeler supports more than 30 kinds of objects, so displaying this amount of items on a single menu can be pretty annoying. So, in order to make the visualization of the mentioned menu a bit better we made this change.
Another improvement is the ability of pasting multiples times a copied object. This feature works only with copy/paste operation without remove the pasted objects from the clipboard, for cut/paste the behavior is unchanged.
The resize parameters of the data manipulation form was adjusted because of a strange behavior of that dialog on Windows systems that could cause the window to be resized to a height bigger than the screen limits causing rendering glitches when the data grid was loading a table with lots of rows. A bug on that dialog was also fixed and was related to a wrong deletion of new rows (the ones added but not saved).
Some other fixed bugs are: the incorrect extraction of domain constraints during reverse engineering; FK relationships not being correctly removed when the user was changing their respective foreign keys; a broken SQL code being generated when the last column of a table had its SQL code disabled. For the list of all new features, improvements and bug fixes of this release, please, refer to CHANGELOG.md.
For now, that's what I have for you! :) Please, don't forget to report any bug found or even a missing feature that you'd like to see in pgModeler. Well, I'll be a bit away from coding because I need to prepare my presentation at PGConf.Brasil 2019 where I'll have the chance to show pgModeler in action!
Bye! ;)
Add new comment