3.33. User-defined types
User-defined types are objects that create new data types that can be used by other objects in the database. In PostgreSQL, it's possible to configure four kinds of user-defined types, being them: base, enumeration, composite, and range. Each type has its own set of attributes and configuration complexity and to provide a better explanation about them, this section was subdivided into four sections which will detail each type separately.
3.28.1. Base types
Base or scalar types are elementary data types used in the same way as the PostgreSQL built-in ones. Creating base types is quite advanced and requires the use of C-based functions. Details about these functions will not be covered by this documentation.
In general, to create a base type, you will need to define at least two functions called, respectively, input and output. The input function converts the external textual representation of the type to its internal representation. The output function does the reverse operation, that is, converts the type from its internal representation to an external textual one. Other optional attributes can be assigned to the type and they are described in the table below.
Due to the number of attributes used to create base types, pgModeler separates them into two tabs: Functions and Attributes. The first tab is used to configure the two mandatory functions as well as other optional ones, and the second tab is used to configure advanced attributes for the type. You seldom need to use the advanced attributes but they are present for those users intending to create a more elaborate data type.
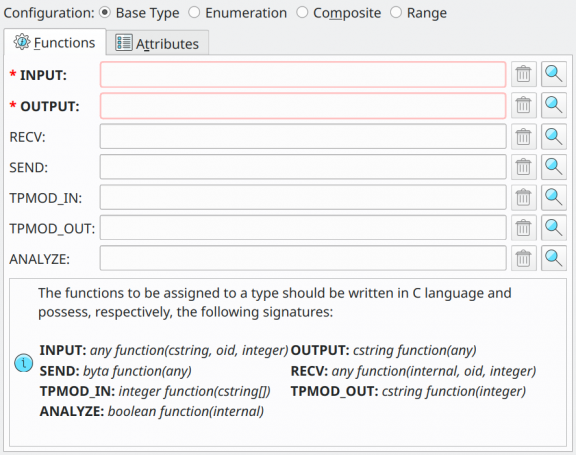
| Attribute | Description |
|---|---|
INPUT |
This function converts the external textual representation of the type to its internal representation. This function should have the signature: any function(cstring, oid, integer). |
OUTPUT |
This function converts the internal representation of the type to its external textual representation. This function should have the signature: cstring function(any). |
RECV |
This function converts the external binary representation of the type to its internal representation. This function should have the signature: any function(internal, oid, integer). |
SEND |
This function converts the internal representation of the type to its external binary representation. This function should have the signature: bytea function(any). |
TPMOD_IN |
This function validates the literal type modifier for the one being created. An example of a type modifier is the length for varchar(20) or the base and precision for numeric(10,2). The input for this function is a cstring array and it should be internally processed by the function and the return should be a non-negative integer indicating the type modifier. This function should have the signature: integer function(cstring[]). |
TPMOD_OUT |
This function converts the internal type modifier representation (single non-negative integer) back to the literal representation. This function should have the signature: cstring function(integer). |
ANALYZE |
This function is responsible for performing type-specific statistics collection for columns of the data type being created. This function must have the signature: boolean function(internal). |
Continuing to detail the base type, the image below shows the advanced attributes used to create a more detailed data type. Most of them aren't often used, anyway, they all will be described.
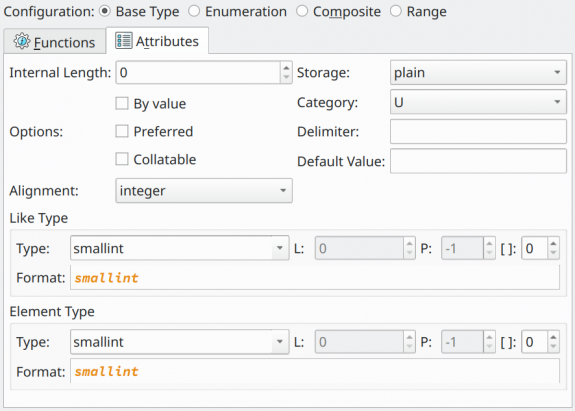
| Attribute | Description |
|---|---|
Internal Length |
Defines the internal length of the type being configured. The default value 0 means that the type has a variable length. |
Storage |
Specifies the storage mode for a variable-length type. Four modes are accepted: plain, extended, external, and main. The plain mode indicates that the type is stored in-line and uncompressed. The extended mode tells the system to try first to compress a long value or move this value out of the main table if it's still too long. The external mode allows the value to be moved to the main table without trying to compress it. The main mode allows value compression but discourages moving it to the main table. |
Options |
A set of optional flags assigned to the type. By value indicates that values of the new type are passed only by value rather than by reference. Preferred indicates that the type is preferred in its category. This parameter also helps the system to use implicit casts in case of ambiguity. Collatable indicates that the type's operations can use collation information. |
Category |
Specifies in which category the new data type fits. Details about categories can be found in the official documentation. |
Delimiter |
Defines the character used as the delimiter between values when this type is used as an array. |
Default Value |
Defines the default values for the data type. |
Alignment |
Specifies the storage alignment for the new type. Four values are accepted: integer, char, smallint, and double precision. |
Like Type |
Indicates a previously defined type from which the new type will have the same representation. |
Element Type |
Indicates the type of the elements when the newly configured type is an array. |
3.28.2. Enumeration types
Enumeration types are data types that are composed of a static set of literal values. This data type is equivalent to the enum types existent in many of the programming languages. Its attributes are described below.
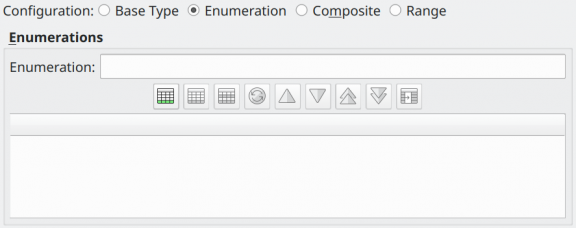
| Attribute | Description |
|---|---|
Enumerations |
This list controls the set of enumerations available for the type. To create a new element, use the field Enumeration. |
Enumeration |
Creates a single enumeration in the type. |
3.28.3. Composite types
Composite types are objects which contain a set of named attributes each one with its own data type. These types resemble the structs present in some programming languages. Additionally, a composite type is basically the same as a row data type of a table but the advantage of the former is that users don't need to explicitly create a table when all that is desired is to define a single type. Composite types can be quite useful as function arguments and return types.
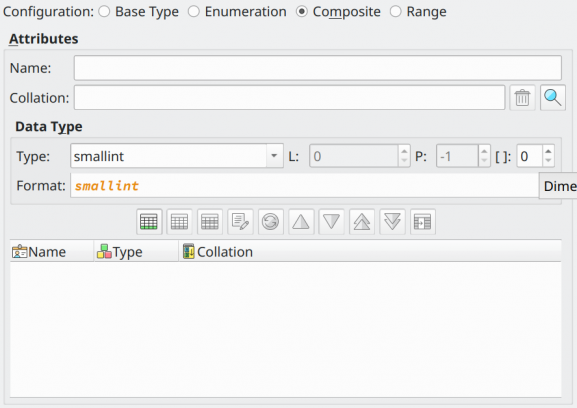
| Attribute | Description |
|---|---|
Attributes |
This group of fields reunites all attributes needed to configure a composite type. |
Name |
Name of an attribute of the type. |
Data Type |
Data type used by the attribute. |
3.28.4. Range types
Range data types represent an interval of values of an element type (also known as range subtype). These types are very useful because they are capable to represent many element values in a single range value. In other words, range types can be used when you need to work with an interval of values without the need to create auxiliary columns to denote their start and end. For instance, let's say you need to create a range of timestamp values, instead of using two columns like start_date and end_date you can just use one column configured with the built-in type tsrange (timestamp range). This type will handle all the operations needed to compare a single value against the entire range and many other features. A complete list of built-in range data types is available in PostgreSQL manuals.
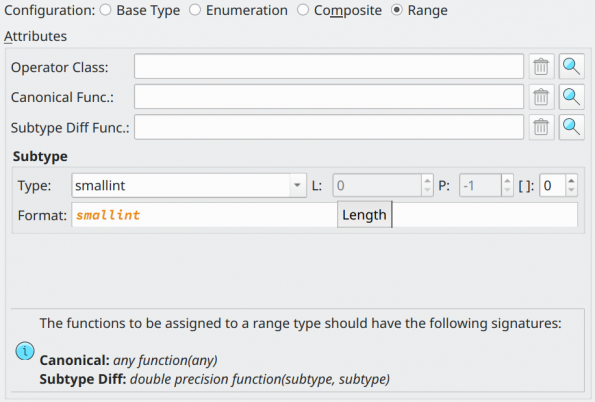
| Attribute | Description |
|---|---|
Operator Class |
The name of the btree operator class associated with the range subtype. This operator class is used to determine how values can be sorted. |
Canonical Func. |
This function is used to convert the range internal values to a canonical form. It must have the signature: any function(any). The function differs from the one stated in the PostgreSQL documentation, so refer to the note at the end of section Base types above to understand why this function is written this way. |
Subtype Diff Func. |
This function compares two values of Subtype and returns a double precision value representing the difference between them. This provides better efficiency of GiST indexes associated with columns with this range data type. |
Subtype |
Configures the internal element type handled by the range type. |
User-defined types DDL
https://www.postgresql.org/docs/current/static/sql-createtype.html
Data type catogories
https://www.postgresql.org/docs/current/static/catalog-pg-type.html#CATALOG-TYPCATEGORY-TABLE
Enum types details
https://www.postgresql.org/docs/current/static/datatype-enum.html
Range types details
http://www.postgresql.org/docs/current/static/rangetypes.html