3.10. Relationships
Relationships are the entities used to represent the link between two tables or between a table and a view. To provide easiness and flexibility when linking tables, pgModeler implements nine different relationship types each one with its proper semantics, being them: one-to-one (1:1), one-to-many (1:n), many-to-many (n:n), self-relationship, generalization or inheritance, copy, foreign key generated relationship, dependency, identifier, and partitioning.
For some kinds of relationships (1:1, 1:n, n:n), there is a mechanism called column propagation which automatically creates columns and constraints in one of the involved tables. Columns propagated by the relationships are automatically named and graphically represented in a different format (by default, they are the ones with green text color and italic font style). Normally, these objects cannot be modified directly, and in some cases, pgModeler will raise errors if the user tries any operation like deleting or modification over them.
Two special relationships are created automatically in certain cases and cannot have some of their attributes handled directly by the user: foreign-key generated relationships (in short, fk relationships) and relationships between tables and views which are used only to denote the dependency of the view to the linked table.
Relationships can have their own attributes and constraints, where the latter are obligated to be associated with the former. The attributes are converted into columns when the relationship is validated and connected to the tables.
Finally, tables can have optional or mandatory participation in the relationship known as cardinality. Cardinality affects directly all the objects generated by the relationship. In pgModeler, relationships can be represented in two different notations: classical entity-relationship notation and crow's foot notation (see the image below). In the next subsections, all relationship types will be detailed.
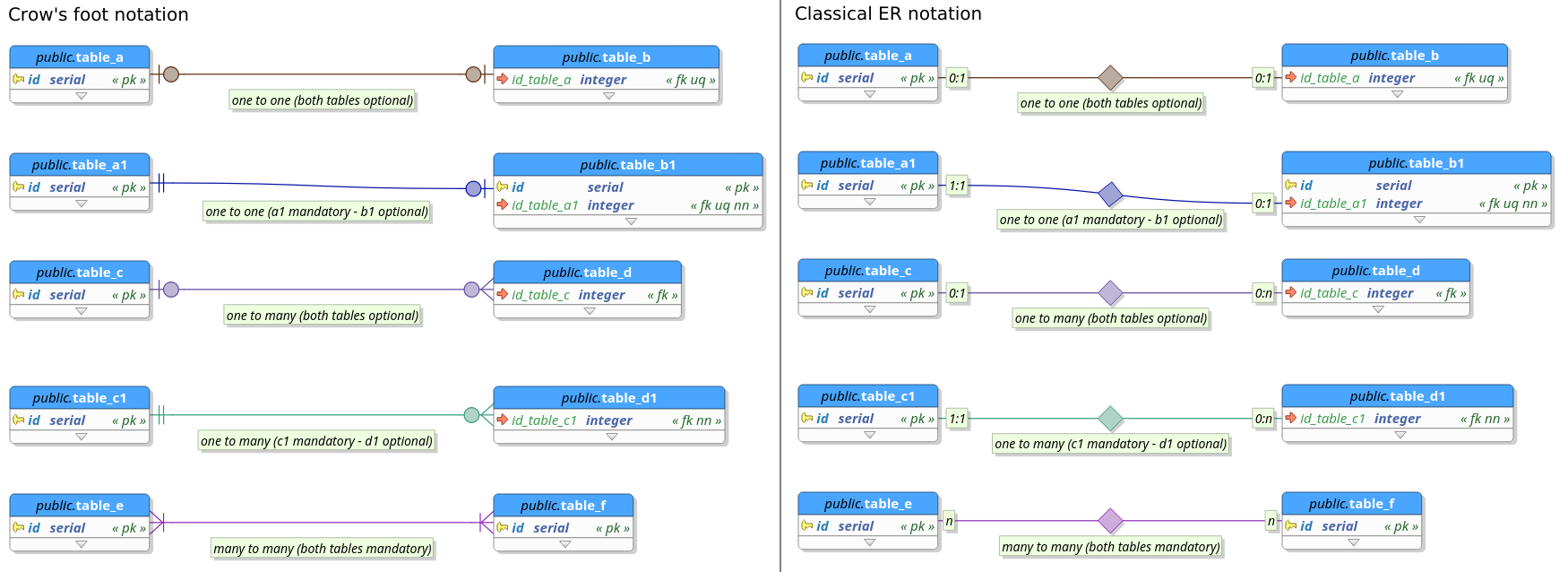
3.10.1. One to one (1:1)
The semantics of this relationship can be described as something like this: “an item in table A has linked to it one item of table B”. In practice, foreign key columns in tableB are filled with the values of primary key columns of tableA. The restriction here is that two different items in tableB can't reference the same item in tableA. To ensure this uniqueness, a unique constraint is created and assigned to the foreign key columns in tableB. The column propagation is available for this kind of relationship and depends on the cardinality combination used, as seen below:
Cardinality: tableA(0,1) —◇— tableB(0,1)
- Columns, attributes, and constraints are always added to the destination table (last selected one –
tableBin the picture above) in order to represent the relationship. - The columns that compose the foreign key accept null values.
- The policy for the
DELETEevent on the foreign key isSET NULL. - The policy for the
UPDATEevent on the foreign key isCASCADE. - A unique constraint is created using the same columns of the foreign key to represent the uniqueness of the entity
tableA. This constraint is added totableB.
Cardinalities: tableA(1,1) —◇— tableB(0,1) and tableA(0,1) —◇— tableB(1,1)
- Columns, attributes, and constraints are always added to the table in which the cardinality is
(0,1)(in the sample image is thetableB). - The columns that compose the foreign key don't accept null values.
- The policy for the
DELETEevent on the foreign key isRESTRICT. - The policy for the
UPDATEevent on the foreign key isCASCADE. - A unique constraint is created using the same columns of the foreign key to represent the uniqueness of the entity, in which the cardinality is
(1,1).
Cardinality: tableA(1,1) —◇— tableB(1,1) [not implemented]
- This cardinality combination is not implemented because it requires merging the involved tables, which may break the user's modeling. An error will be raised if the user persists in the creation of a relationship with this cardinality.
3.10.2. One to many (1:n)
The semantics of this relationship is: “An item in table A has linked to it many items of table B”. To clarify, unlike the one-to-one relationship, foreign key columns in tableB are filled with the values of primary key columns of tableA, and tableB is allowed to have one or more items that reference the same item in tableA. Likewise, the one-to-one relationship, the cardinality affects how columns and constraints are propagated as detailed below:
Cardinality: tableA(0,1) —◇— tableB(0,n)
- Columns, attributes, and constraints are always added to the destination table or to the
(n)side (tableBin the sample image above) to represent the relationship. - The columns that compose the foreign key accept null values.
- The policy for the
DELETEevent on the foreign key isSET NULL. - The policy for the
UPDATEevent on the foreign key isCASCADE.
Cardinality: tableA(1,1) —◇— tableB(0,n)
- Columns, attributes, and constraints are always added to the destination table or the
(n)side (tableBin the sample image) to represent the relationship. - The columns that compose the foreign key don't accept null values.
- The policy for the
DELETEevent on the foreign key isRESTRICT. - The policy for the
UPDATEevent on the foreign key isCASCADE.
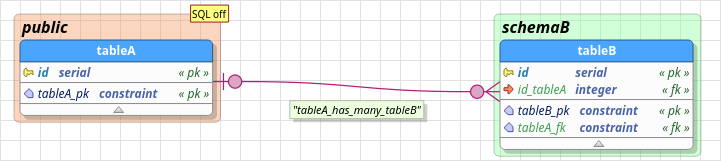
3.10.3. Many to many (n:n)
The semantics of this relationship is: “many items in table A have linked to them many items of table B”. This kind of link creates an intermediate table to simulate the relationship between the involved tables. Thus, the foreign key columns on the intermediate table are filled with the values of the primary key columns of both tableA and tableB. The cardinality is ignored for this kind of relationship.

Cardinality: ignored
- An intermediate table is created to represent this kind of relationship.
- Two foreign keys are created on the intermediate table, each one referencing the involved tables.
- A primary key is created on the intermediate table using the columns that compose both foreign keys.
- User-defined attributes and constraints are added to the intermediate table.
- The policy for the
DELETEevent on the foreign keys isRESTRICT. - The policy for the
UPDATEevent on the foreign keys isCASCADE.
3.10.4. Self-relationship
Self-relationship works likewise the regular 1:1, 1:n, and n:n relationships, which means, all rules of cardinality and object creation applied to them are valid for this kind. The difference is that only one table is involved and it is linked to itself. To create a self-relationship the user should press and hold Shift key when using the relationship tool before clicking the desired table. The image below shows an example of a self-relationship.
3.10.5. Inheritance
This kind of relationship implements the table inheritance as PostgreSQL does. Visually, columns are copied from the parent table to its child, in the image below, from tableA to tableB. One point must be observed here: the columns are copied to the child table but will not appear in the generated SQL code since PostgreSQL is responsible for handling the inherited columns. Also, as in PostgreSQL, if the same columns exist on both tables, they will be merged on the child only if their data types are the same. In practice, the columns on the child table are kept in their original configuration. When the columns are incompatible, pgModeler will raise an error and abort the relationship creation.
Finally, when creating an inheritance between tables, only check constraints are copied to child tables, if and only if the No inherit attribute is unchecked in these constraints. Other kinds of constraints aren't copied and the user must recreate them on the child table if they are needed, thus, it's quite important to be careful when handling multiple inheritances due to this side effect.
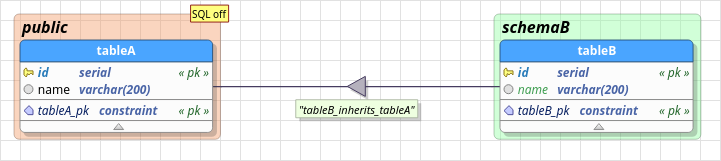
3.10.6. Copy relationship
Copy relationship partially implements the table copy as PostgreSQL implements it through the usage of the LIKE keyword. Unlike inheritance, a copy relationship will not merge columns that already exist on the derivative tables, instead, an error will be raised because the premise of copy is to create a table completely decoupled from its parent one.
Observe the slight difference between an inheritance relationship in the previous section and the copy relationship in the image below. The dashed line of the latter only denotes a transient dependency between the involved tables because the child depends on the parent only at design time due to internal validation reasons. When the model is exported to SQL code, two decoupled and independent tables will be created. Even the reverse engineering feature isn't able to identify if a table was created from a copy relationship.
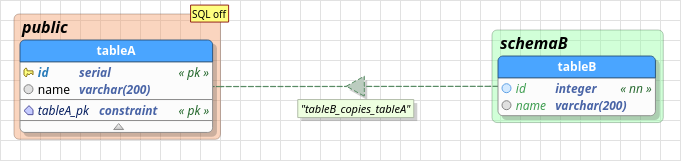
3.10.7. FK relationship
This special relationship has its semantics and rendering defined by the combination of the constraints (primary key, foreign key, unique, and not null) presented in the tables. So, based upon this situation, pgModeler will render an fk relationship as one-to-one or one-to-many (including their cardinality variation - optional or mandatory) just by analyzing the mentioned constraints. In the image below we can see four different fk relationships that represent, respectively, (0,1) —◇— (0,n) (green), (1,1) —◇— (0,n) (red), (1,1) —◇— (0,1) (purple), (0,1) —◇— (0,1) (orange).
FK relationships can't be directly modified by the user, except for their basic attributes like the name, line color, and position of the labels, for example. This kind of object is automatically created whenever the user manually adds a foreign key to a table, thus, pgModeler detects which table is being referenced in the foreign key constraint and links the two tables. Unlike the original one-to-one and one-to-many relationships, this one doesn't accept extra attributes or constraints. The only special behavior of this relationship is that if the user deletes it from the model, the foreign key that generated it will be wiped out from the table as well.
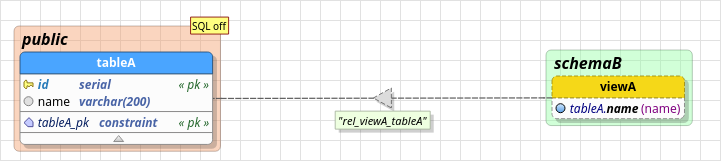
3.10.8. Dependency
This relationship is similar to the copy one in style and semantics, but it's applied to denote a link between a table and a view. Additionally, this object can't own attributes or constraints, and the user can only handle its name and label position.
3.10.9. Identifier relationship
This relationship implements the concept of strong and weak entities. Basically, the weak entity (tableB in the image below) is the table in which tuples only exist when the referenced tuples on the strong entity (tableA) also exist. This means that if the item on the strong entity is deleted, all the items on the weak entity that reference the deleted one are removed as well.
Additionally, this relationship creates a primary key on the weak entity hence the name identifier relationship. In case of a primary key already exists on the weak entity then the created primary key is merged into the existing one. Finally, this kind of relationship is graphically identifiable by the thick line linked to the weak entity. Also, only one-to-one and one-to-many relationships can be marked as identifiers.
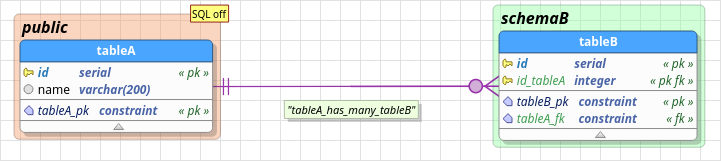
3.10.10. Partitioning relationship
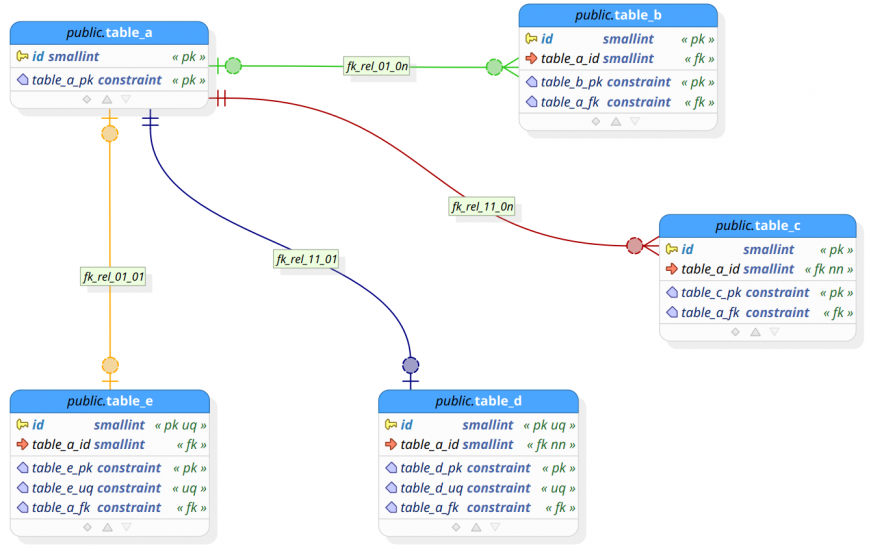
In PostgreSQL, table partitioning refers to the action of splitting one large table into smaller physical pieces. There are several benefits that we can gain from this technique, for instance, improved query performance, separation of data that is frequently accessed from seldom-accessed data, and many others. In previous pgModeler releases, there were some ways to simulate table partitioning (as well as in PostgreSQL 9.6 and below) by using a combination of inheritance and triggers, which could be very difficult to maintain in certain situations. So, in pgModeler 0.9.2, the declarative table partitioning introduced by PostgreSQL 10 and improved by version 11 has been added, making the partitioning easier to create and maintain.
In pgModeler, table partitioning is configured by using three features: the partitioning strategy, the partition keys (both configured in the partitioned table), and a partitioning relationship. The partitioning strategy, or simply partitioning, is the mode in which PostgreSQL will handle the data separation in the main table (called the partitioned table) and in its partitions. There are three supported partitioning modes: LIST, RAGE, and HASH. The partition keys are a set of columns of the partitioned table or expressions that are used to define the key columns or values used to determine the correct partition to which the inserted data will be routed, for instance. Finally, a partitioning relationship is used to denote graphically that a table is a partition of another, as well as to configure the partition bounding expression that is used to route the data to a specific partition based on the value(s) in it.

The syntax of the bounding expression is tied to the partitioning strategy adopted and has different forms of writing, thus pgModeler helps the users by creating a template expression when a new partitioning relationship is being created.
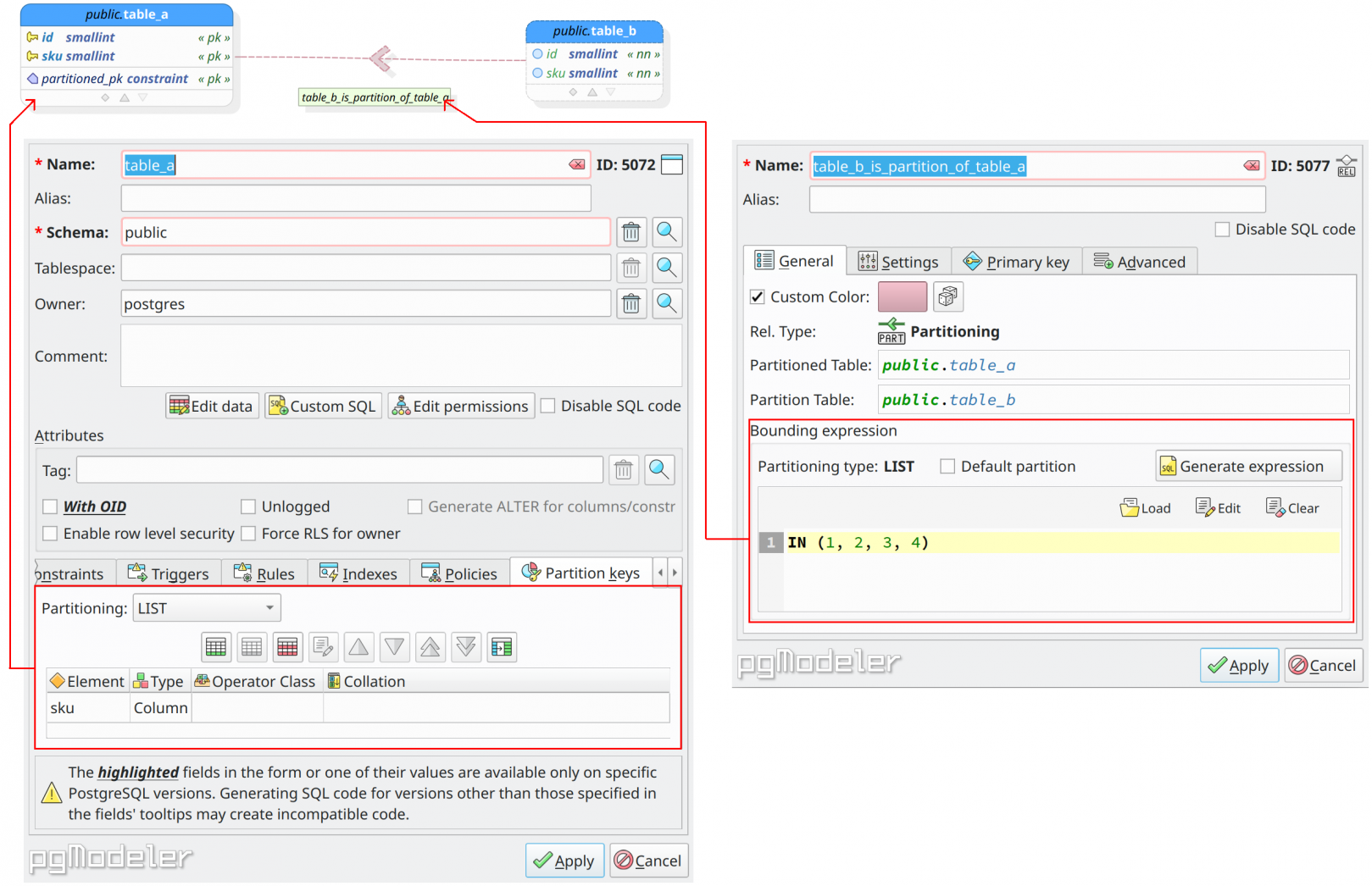
In the image above, we have a small partitioning hierarchy created. The relationship between table_a (partitioned) and table_b (partition) is a partitioning relationship denoting that table_a somehow will "redirect" data to table_b when some conditions are met. Note that the partitioning relationship has its own descriptor or identifier: an arrow always pointing from the partition table to the related partitioned table, which makes its representation unique among all kinds of relationships. Even the relationship's name label enforces that it represents a link between a partition and its partitioned.
Still in the image, in the table properties dialog, the highlighted section contains the partitioning strategy used by table_a as well the partition key(s) (in the grid at the bottom) for the partitioning hierarchy. Now, in the relationship properties dialog, the highlighted area is the partition bounding expression used to define values of the partition key defined in table_a which will be routed to table_b.
3.10.11. Attributes and constraints
Attributes are visually represented by the orange circles that appear next to the relationship descriptor (in classical ER notation) or in the center of the line (in crow's foot notation) and are nothing more than columns assigned to the relationship. These attributes are inserted into the tables when the relationship is connected to the entities.
Relationship constraints are the same as the ones used for tables, but the only difference is that they can only reference relationship attributes. These objects are added to tables like the relationship attributes. Except for primary keys, all other types of constraints can be created in the relationships. Primary keys are treated in a special way as described in the next section.
3.10.12. Editing form
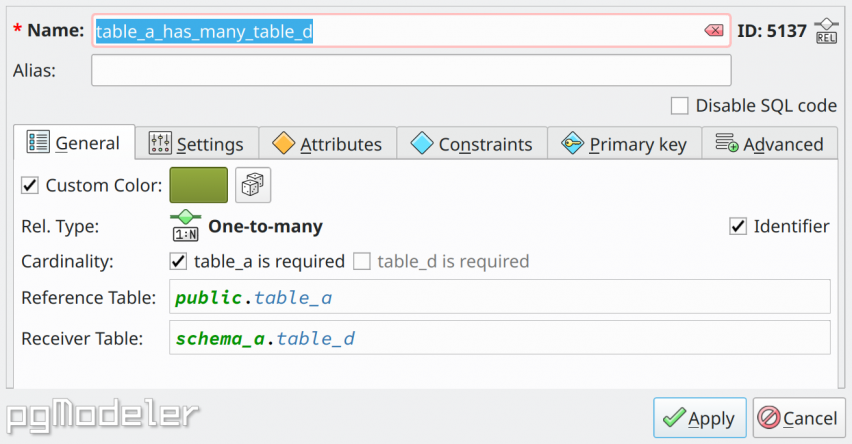
Being the most complex objects in pgModeler, relationships have an editing form that tries to minimize this complexity by separating fields into different sections. This dialog is a polymorphic one, meaning that some fields will be absent depending on the relationship type. All the fields in the form are described below. In General section is where basic details of the relationship are configured. They are detailed in the next table.
| Attribute | Description |
|---|---|
Custom color |
Specifies a custom color for the relationship line and descriptor. |
Rel. Type |
This read-only field denotes the type of the relationship being handled: one-to-one (1-1), one-to-many (1-n), many-to-many (n-n), generalization or inheritance (gen), dependency or copy (dep) and fk relationship (fk). |
Identifier |
Marks the relationship as an identifier. This option is available only for one-to-one and one-to-many relationships. |
Cardinality |
Indicates which tables are of mandatory participation. This option is available only for one-to-one and one-to-many types of relationships. |
Reference Table |
Table from which columns are copied to the receiver table. |
Receiver Table |
Table to which columns from the reference table will be copied. For many-to-many relationships, this field is renamed to Reference Table too, since both tables serve as a reference to create the intermediate table. |
Gen. Table Name |
Sets the name of the intermediate table generated by a many-to-many relationship. |
Bounding expression |
This group contains a set of fields used the determine the bounding expression for a partitioning relationship. |
Default partition |
Indicates that the partition table of the configured relationship is the default for the whole partition hierarchy. |
Generate expression |
This button generates a template bounding expression for a partitioning relationship depending on the partitioning type used by the partitioned table associated with the relationship. |
In the Settings tab is where the user configures the majority of attributes of the relationship. This tab is not available for all kinds of relationships. The fields of this tab are described below.
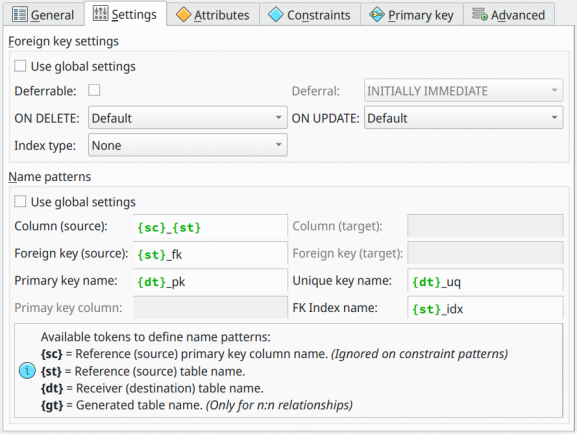
| Attribute | Description |
|---|---|
Foreign key settings |
This group of fields overrides the default configuration for any generated foreign key. |
Copy Options |
Indicates which attributes must be copied from the reference table when dealing with a copy relationship. You can indicate that the relationship must include or exclude some attributes from the reference table, or use the default behavior, which is to copy only column names, their data types, and not-null constraints. Attributes that can be copied: DEFAULTS, CONSTRAINTS, INDEXES, STORAGE, COMMENTS, or ALL. |
Name Patterns |
This group of fields is used to define custom name patterns for each generated object. Details about name patterns are described in the next section. This option is available only for one-to-one, one-to-many, and many-to-many relationships. |
The remaining tabs on the relationship form are described as follows:
| Attribute | Description |
|---|---|
Attributes |
This tab is used to configure relationship attributes. This option is available only for one-to-one, one-to-many, and many-to-many relationships. |
Constraints |
This tab is used to configure relationship constraints. This option is available only for one-to-one, one-to-many, and many-to-many relationships. |
Primary key |
This tab is used to configure the special relationship primary key. This constraint uses exclusively the columns generated by the relationship as well as its attributes to configure a primary key that will be added to the receiver table when connecting the relationship. |
Advanced |
This tab lists all objects generated by the relationship or, in the case of fk relationships, the foreign key that represents it. Users can see details about these objects by opening them on their respective editing forms in read-only mode. |
3.10.13. Name patterns
Column propagation is a powerful mechanism implemented by pgModeler. It can accelerate productivity by automatically creating columns and constraints as the user links tables using relationships. The only downside of this feature is the lock-in of any created object, meaning that the user can't change any of their attributes, including names. To workaround this issue, pgModeler can define name patterns that are parsed during relationship creation time and used to generate the name of any object allocated.
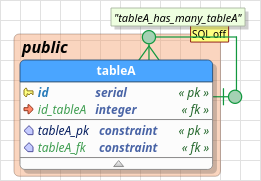
Basically, patterns are the joint of predefined tokens and additional characters added by the user. Four are the recognized tokens: {sc}, {st}, {dt}, and {gt}. Note that any token must be enclosed in {} to be parsed by pgModeler. The meaning of each token is described below:
{sc}: stands for the name of the source column or the primary key column used as a reference.{st}: stands for the name of the source or reference table.{dt}: stands for the name of the destination or receiver table.{gt}: stands for the name of the generated (or most commonly, the intermediate) table name. This token is used only when the relationship is of type many-to-many.
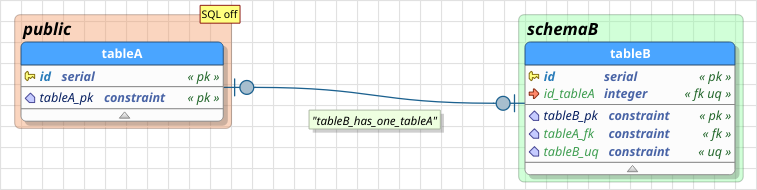
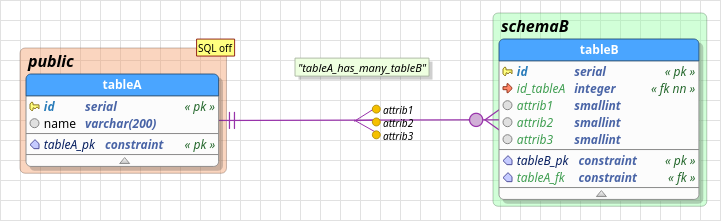
To clarify the token usage, let's take a look at the image below. The relationship links tableA to tableB, in this case, the first is the source or reference, and the last one is the destination or receiver, because it is the table that receives all generated objects. Note the column id_tableA on tableB, this column was generated through the pattern {sc}_{st} where {sc} is replaced by the primary key column id of the table tableA and {st} replaced by the name of reference table, again, tableA.
The same rule is valid for the generated foreign key tableA_fk; the name pattern used was {st}_fk. In this case, there is a static text _fk that is kept when pgModeler translates the pattern because the text is not enclosed by {} as the rule states. The user can specify at most eight name patterns, being them: two for columns, two for generated foreign keys, two for the primary keys, one for the generated unique key, and one for the index generated for columns created by the relationship. Not all fields will be enabled at the same time because the use of a specific name pattern is conditioned on the relationship type currently being handled.
Table partitioning feature
https://www.postgresql.org/docs/current/ddl-partitioning.html